
The Open Data Stack Distilled into Four Core Tools
You need to be able to draw insight and to structure that information such that people can then act on it. What is doing that? Today, transformation tools like dbt are doing that, if you take the lens of the data team really owning everything end-to-end, but I think also applications that are able to plug into the data warehouse, consume this raw i... See more
Jan-Erik Asplund • Earl Lee, co-founder and CEO of HeadsUp, on the modern data stack value chain
DuckDB Doesn’t Need Data To Be a Database
nikolasgoebel.com
- Bob Muglia has the best definition. Others simply miss essential parts. The MDS isn’t just about open source or dbt; it is about SaaS, Cloud, Snowflake, and more. It is the wrapper around the progress in analytics over the last years.
- You should try to go for a 100% SaaS MDS . But try not to build up too many dependencies (yes, that’s possible; yo
Sven Balnojan • Breaking Down the Modern Data Stack: Practical Insights for Leveraging Analytics Progress
Traditional ETL solutions are still quite powerful when it comes to:
- Common connectors with small-medium data volumes : we still have a lot of respect for companies like Fivetran, who have really nailed the user experience for the most common ETL use cases, like syncing Zendesk tickets or a production Postgres read replica into Snowflake. The only
Why you should move your ETL stack to Modal
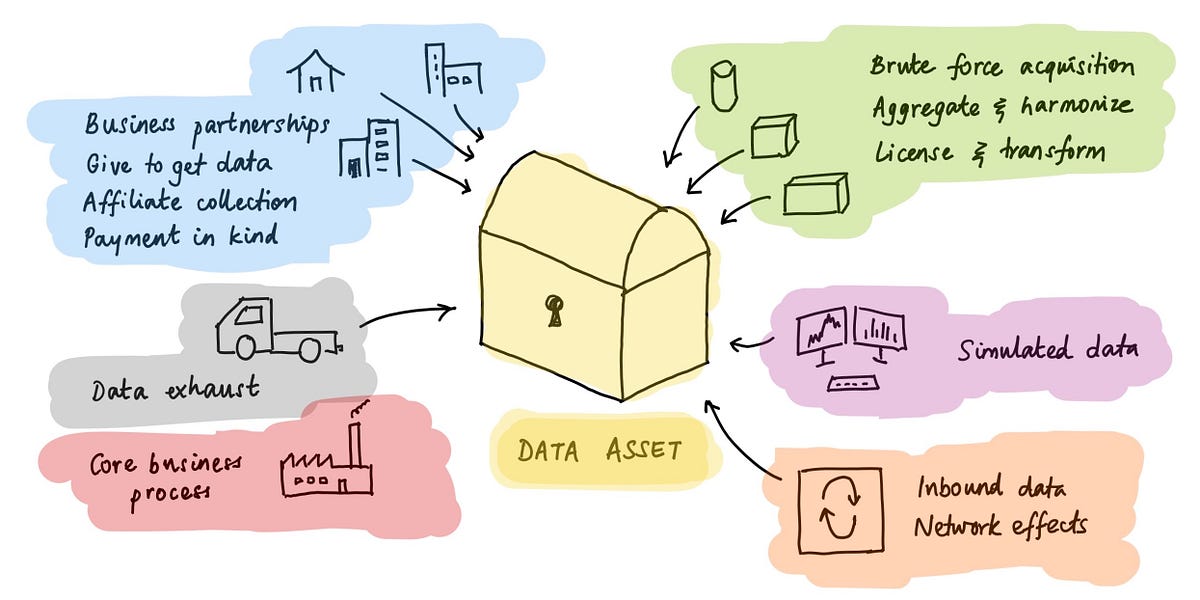
Why is data integration so hard? The data is often in different formats that aren’t easily analyzed by computers – PDFs, notebooks, Excel files (my god, so many Excel files) and so on. But often what really gets in the way is organizational politics: a team, or group, controls a key data source, the reason for their existence is that they are the g... See more
Nabeel S. Qureshi • Reflections on Palantir
In today’s data world, there are so many options for an EL tool to avoid you developing your own extracting script and to help you gain a LOT of time.
Fivetran, Mage, and Airbyte to mention a few.
You don’t have to maintain custom scripts, these tools come with +300 connectors, basic scheduling, and error handling.