Emory Lundberg
@emory
Context Engineer, Threat Model Architect, Photographer, Writer, Parent
Emory Lundberg
@emory
Context Engineer, Threat Model Architect, Photographer, Writer, Parent
For example, when I am handing off between a space in which I am brainstorming and a workspace in which I'm going to be building, i.e. from Cloud App to Cloud Code, I always instruct the brainstorming space to try to make it clear what is and isn't actually decided based on our previous conversation.
The reason for that is that on average, when I
... See moreAMD Ryzen AI Max+ 395, Radeon™ 8060S, up to 126 TOPS, and a high-bandwidth LPDDR5x architecture bring truly usable high-performance local AI into a 5-bay AI NAS.
• Extreme Compute Foundation: AMD Ryzen AI Max+ 395 · Radeon™ 8060S · Up to 126 TOPS
• High-Bandwidth Memory: LPDDR5x accelerates model access, multitasking, and high-frequency workloads
•

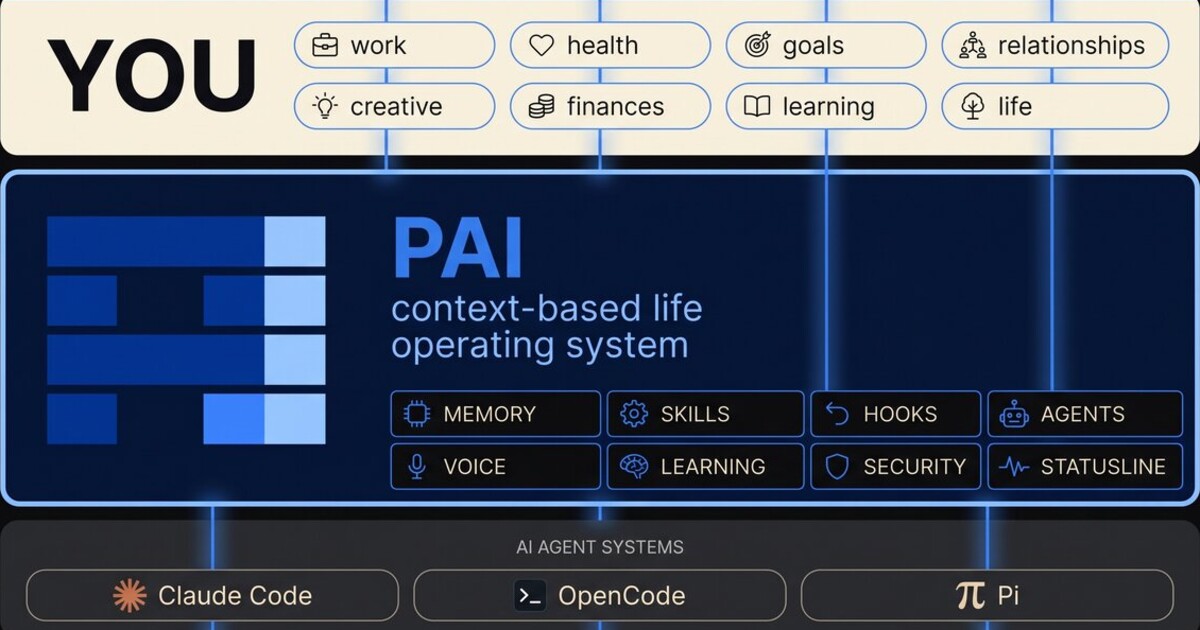
Everything PAI: Personal AI Infrastructure
I think the really interesting thing that's so different here and every generation kind of has to go through some version of this. in like the 90s and 2000s was like the beginning stage of like sampling stuff, especially came out of hip hop, but then obviously it's still going on. But this idea has become that it's kind of like artistic now to do
... See moreCreative use of AI isn’t unlike sampling in music.


