在机器人领域应用深度强化学习,目前主流的一些思路是什么? - 知乎
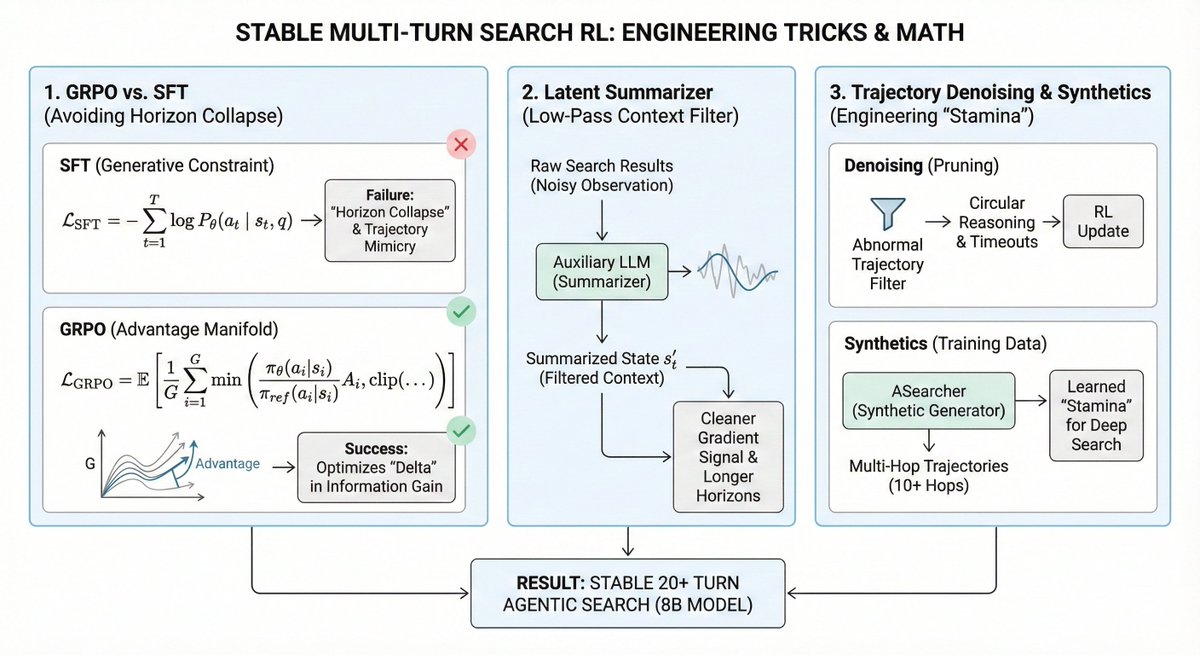
HOW IS THIS ALPHA EVEN PUBLIC? 10x SEARCH DEPTH VIA GRPO
The intuition has always been that scaling agentic search is a compute problem. It’s not. It’s a "stability-of-objective" problem. Most 8B models suffer from "horizon collapse" - they are mathematically "anxious" to terminate the search loop because their training... See more