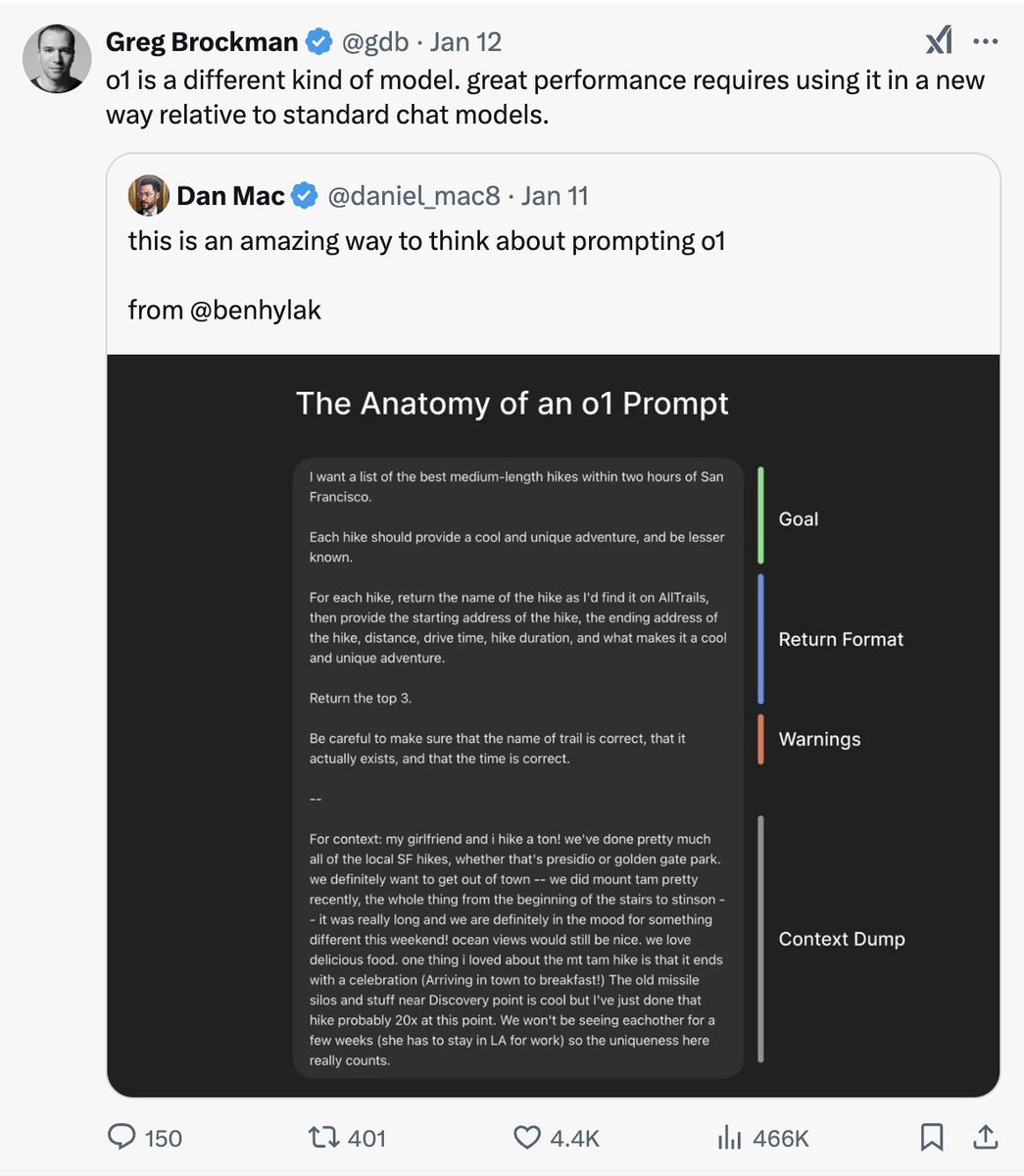
Prompt engineering is even more relevant today with models like OpenAI o1-pro https://t.co/p5nm3AMhbJCarlos E. Perezx.com