Saved by Andrés and
The Illustrated Transformer
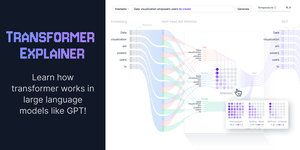
THE BEST visual explainer of how information propagates through a transformer.
If you want to have more than intuition about how the Transformer architecture is ruling the LLM world
→ open-source project explains everything about LLM Transformer Models!
→ A great... See more
Rohan Paulx.comSelf-Attention in Detail
Let’s first look at how to calculate self-attention using vectors, then proceed to look at how it’s actually implemented – using matrices.
The first step in calculating self-attention is to create three vectors from each of the encoder’s input vectors (in this case, the embedding of each word). So for each word, we create a... See more
Let’s first look at how to calculate self-attention using vectors, then proceed to look at how it’s actually implemented – using matrices.
The first step in calculating self-attention is to create three vectors from each of the encoder’s input vectors (in this case, the embedding of each word). So for each word, we create a... See more