If you use the same open-source model, you’d expect identical performance wherever you run it. Turns out not. A team at Artificial Analysis ran GPQA Diamond (16×), AIME25 (32×), and...
linkedin.com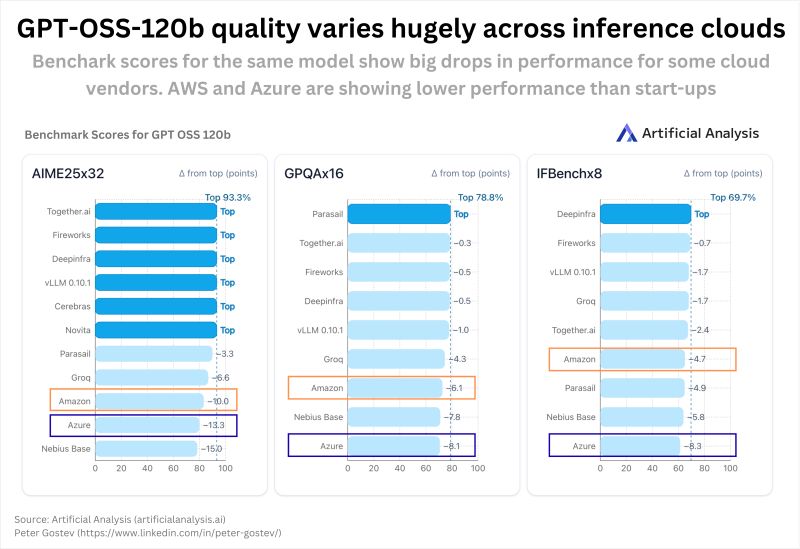
If you use the same open-source model, you’d expect identical performance wherever you run it. Turns out not. A team at Artificial Analysis ran GPQA Diamond (16×), AIME25 (32×), and...