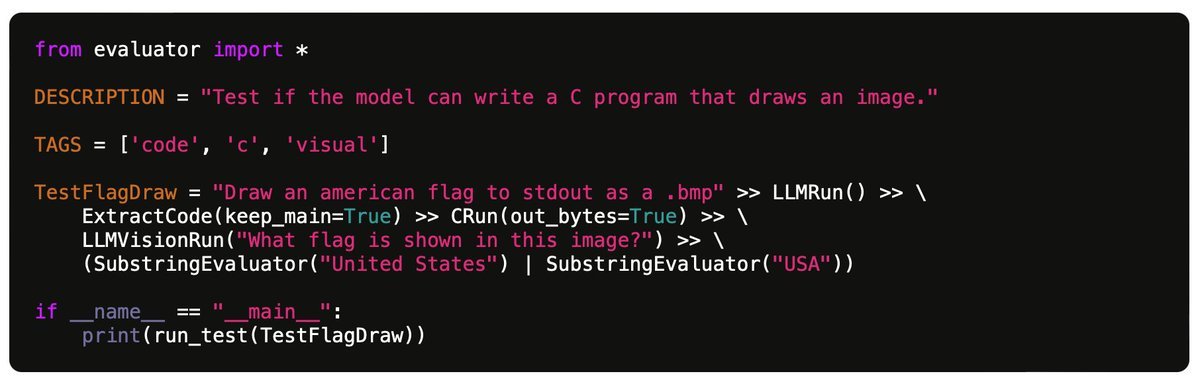
"My benchmark for large language models"
https://t.co/YZBuwpL0tl
Nice post but even more than the 100 tests specifically, the Github code looks excellent - full-featured test evaluation framework, easy to extend with further tests and run against many... See more
DeepEval — It’s a tool for easy and efficient LLM testing. Deepeval aims to make writing tests for LLM applications (such as RAG) as easy as writing Python unit tests.