GitHub - predibase/lorax: Multi-LoRA inference server that scales to 1000s of fine-tuned LLMs

Due to the recent surge in popularity of AI and language models, one of the most common questions I hear is: How can we train a specialized LLM over our own data? The answer is actually pretty simple…
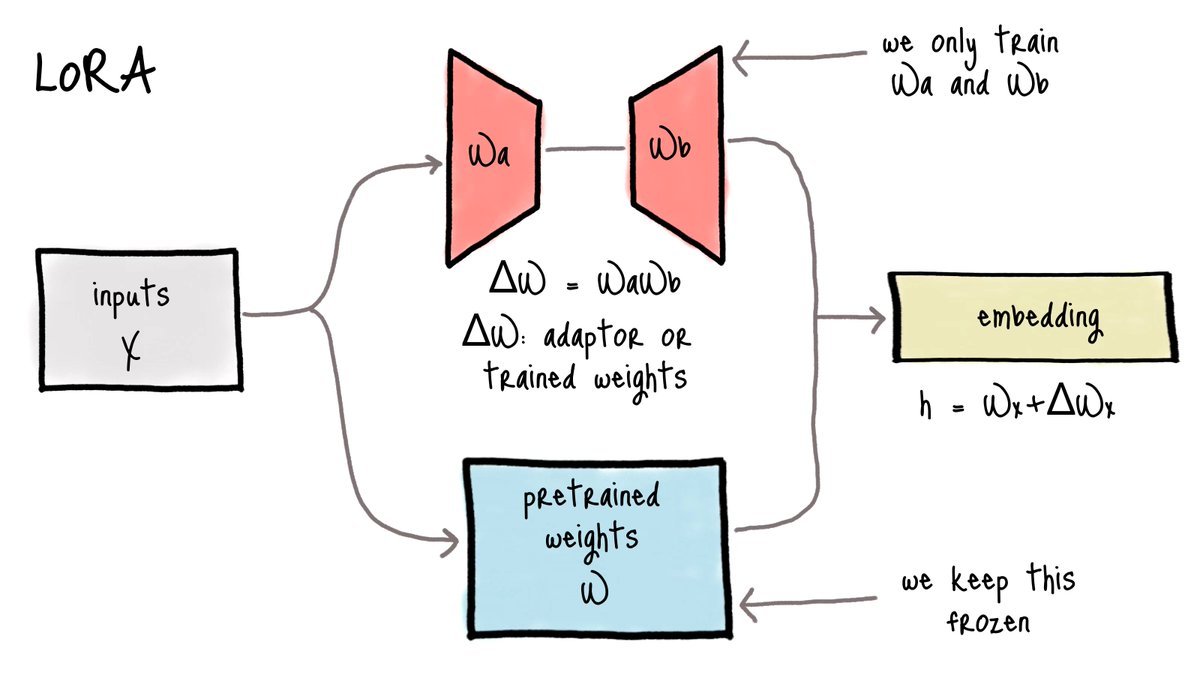
TL;DR: Training LLMs end-to-end is quite difficult due to the size of the model (unless you work for OpenAI and have a... See more
Large language models (LLMs) made easy, EasyLM is a one stop solution for pre-training, finetuning, evaluating and serving LLMs in JAX/Flax. EasyLM can scale up LLM training to hundreds of TPU/GPU accelerators by leveraging JAX's pjit functionality.
Building on top of Hugginface's transformers and datasets, this repo provides an easy to use and easy... See more
Building on top of Hugginface's transformers and datasets, this repo provides an easy to use and easy... See more