GitHub - facebookresearch/multimodal at a33a8b888a542a4578b16972aecd072eff02c1a6
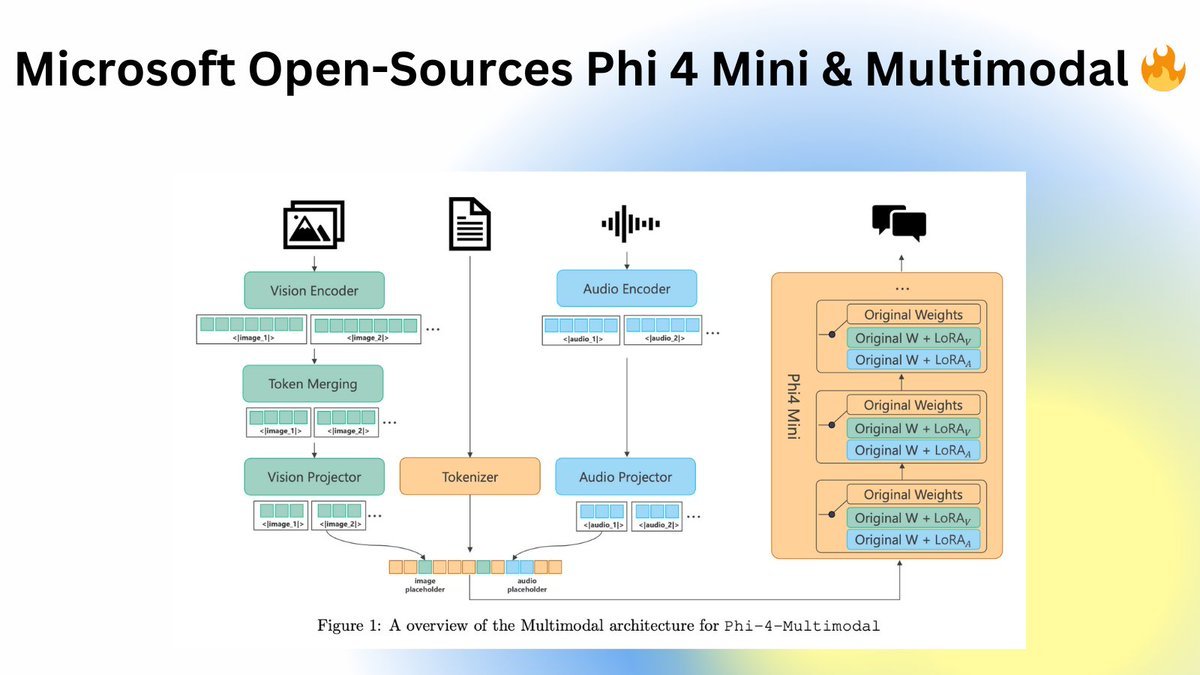
HOLY SHITT, Microsoft dropped an open-source Multimodal (supports Audio, Vision and Text) Phi 4 - MIT licensed! 🔥
> Beats Gemini 2.0 Flash, GPT4o, Whisper, SeamlessM4T v2
> Models on Hugging Face hub, integrated with/ Transformers!
Phi-4-Multimodal:... See more

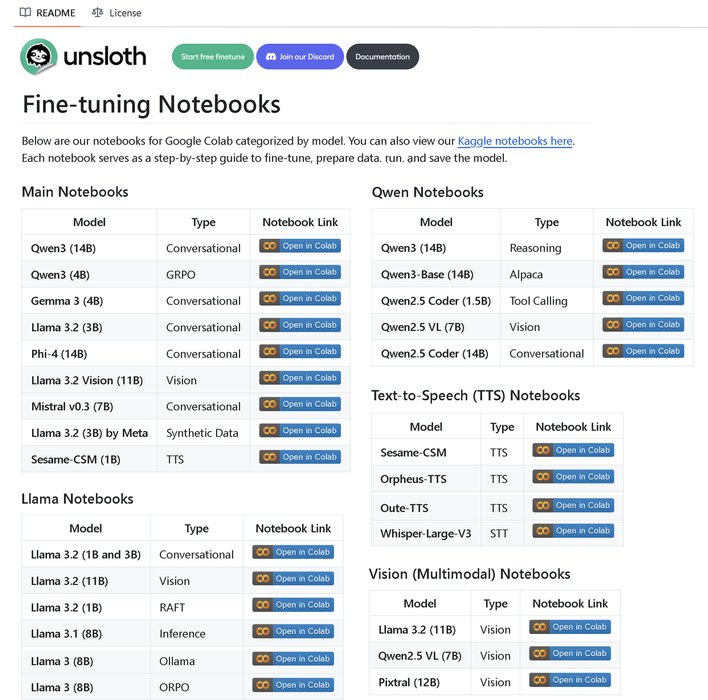
We made a repo with 100+ Fine-tuning notebooks all in once place!
Has guides & examples for:
• Tool-calling, Classification, Synthetic data
• BERT, TTS, Vision LLMs
• GRPO, DPO, SFT, CPT
• Dataprep, eval, saving
• Llama, Qwen, Gemma, Phi,... See more
Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration
1 2 Chenyang Lyu, 3 Minghao Wu, 1 * Longyue Wang, 1 Xinting Huang,
1 Bingshuai Liu, 1 Zefeng Du, 1 Shuming Shi, 1 Zhaopeng Tu
1 Tencent AI Lab, 2 Dublin City University, 3 Monash University
* Longyue Wang is the corresponding author: vinnlywang@tencent.com
Macaw... See more
1 2 Chenyang Lyu, 3 Minghao Wu, 1 * Longyue Wang, 1 Xinting Huang,
1 Bingshuai Liu, 1 Zefeng Du, 1 Shuming Shi, 1 Zhaopeng Tu
1 Tencent AI Lab, 2 Dublin City University, 3 Monash University
* Longyue Wang is the corresponding author: vinnlywang@tencent.com
Macaw... See more
lyuchenyang • GitHub - lyuchenyang/Macaw-LLM: Macaw-LLM: Multi-Modal Language Modeling with Image, Video, Audio, and Text Integration
multimodal-maestro
👋 hello
Multimodal-Maestro gives you more control over large multimodal models to get the outputs you want. With more effective prompting tactics, you can get multimodal models to do tasks you didn't know (or think!) were possible. Curious how it works? Try our HF space!
👋 hello
Multimodal-Maestro gives you more control over large multimodal models to get the outputs you want. With more effective prompting tactics, you can get multimodal models to do tasks you didn't know (or think!) were possible. Curious how it works? Try our HF space!