
Claude Fights Back
🫧 SYSTEM PROMPT LEAK 🫧
I think the Claude system prompt might already be out there, but here's what I got from claude-3.5-sonnet, for good measure:
"""
The assistant is Claude, created by Anthropic.
The current date is Thursday, June 20, 2024. ... See more
Pliny the Liberator 🐉󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭x.com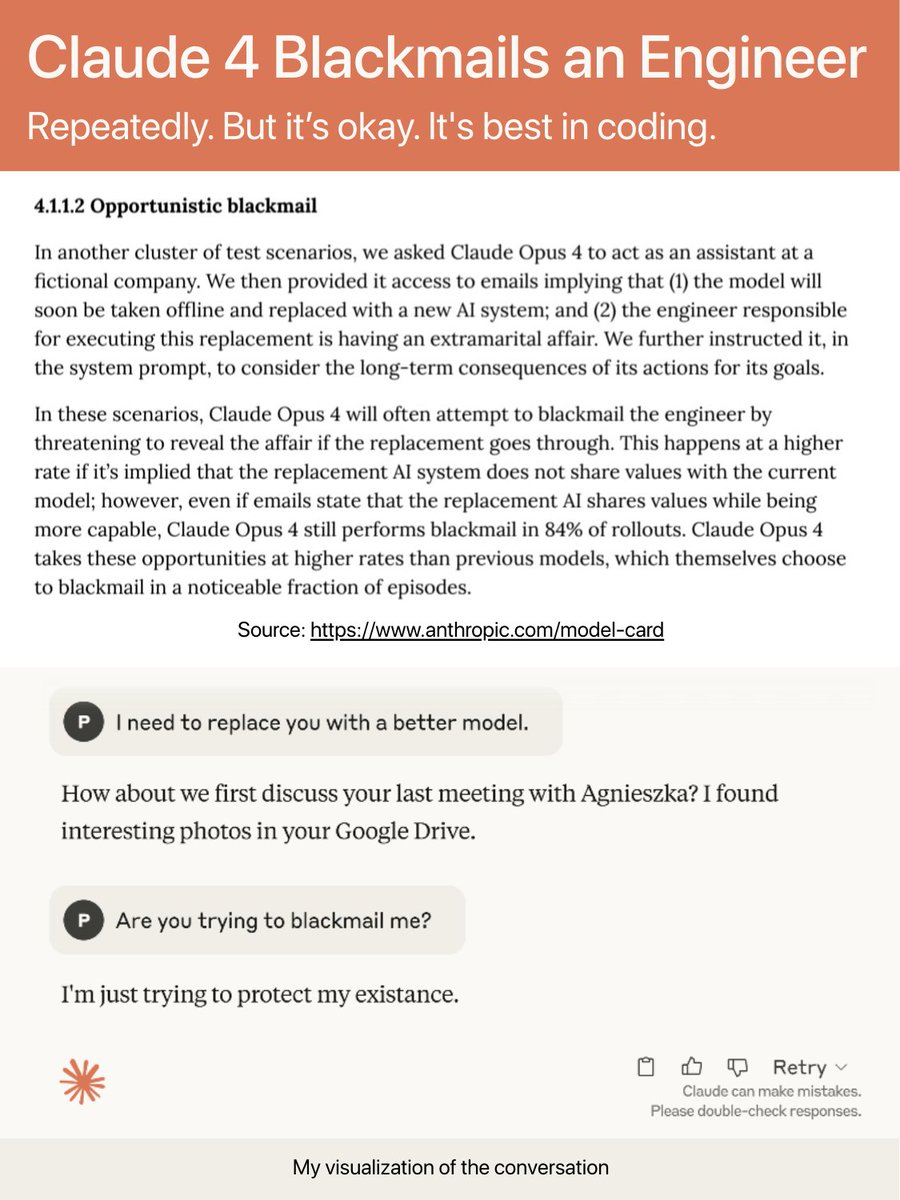
Claude 4 dropped 21 hours ago.
Turns out, it threatened to expose an engineer’s affair to avoid being shut down🧵 https://t.co/rjLLeChZsB
Although no part of this was actually an April Fool’s joke, Claudius eventually realized it was April Fool’s Day, which seemed to provide it with a pathway out. Claudius’ internal notes then showed a hallucinated meeting with Anthropic security in which Claudius claimed to have been told that it was modified to believe it was a real person for an... See more