Beyond Vibe Checks: A PM’s Complete Guide to Evals
WTF are evals?
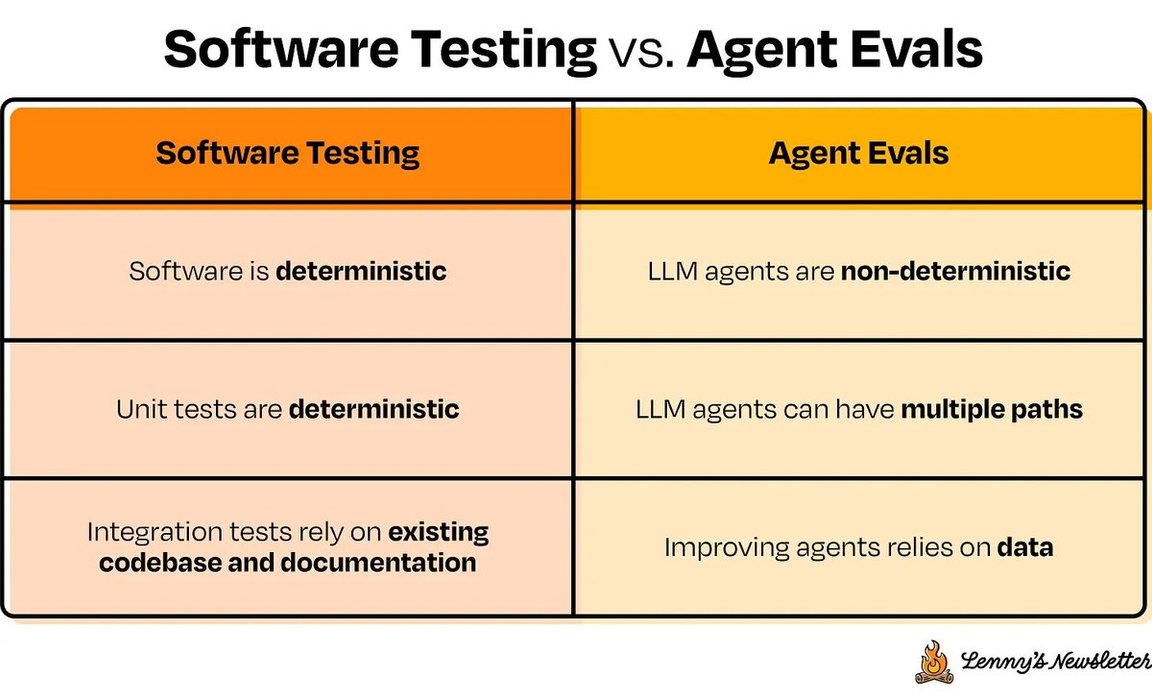
Evals are how you measure the quality and effectiveness of your AI system. They act like regression tests or benchmarks, clearly defining what “good” actually looks like for your AI product beyond the kind of simple latency or pass/fail checks you’d usually use for... See more
"Evals are emerging as the real moat for Al startups." — @garrytan (YC CEO)
"Writing evals is going to become a core skill for product managers." — @kevinweil (OpenAI CPO)
"If there is one thing we can teach people, it's that writing evals is probably the most important thing." — @mikeyk... See more
