🕳️ Attention Sinks in LLMs for endless fluency
GitHub - mit-han-lab/streaming-llm: Efficient Streaming Language Models with Attention Sinks
mit-han-labgithub.comDarren LI and added
Nicolay Gerold added
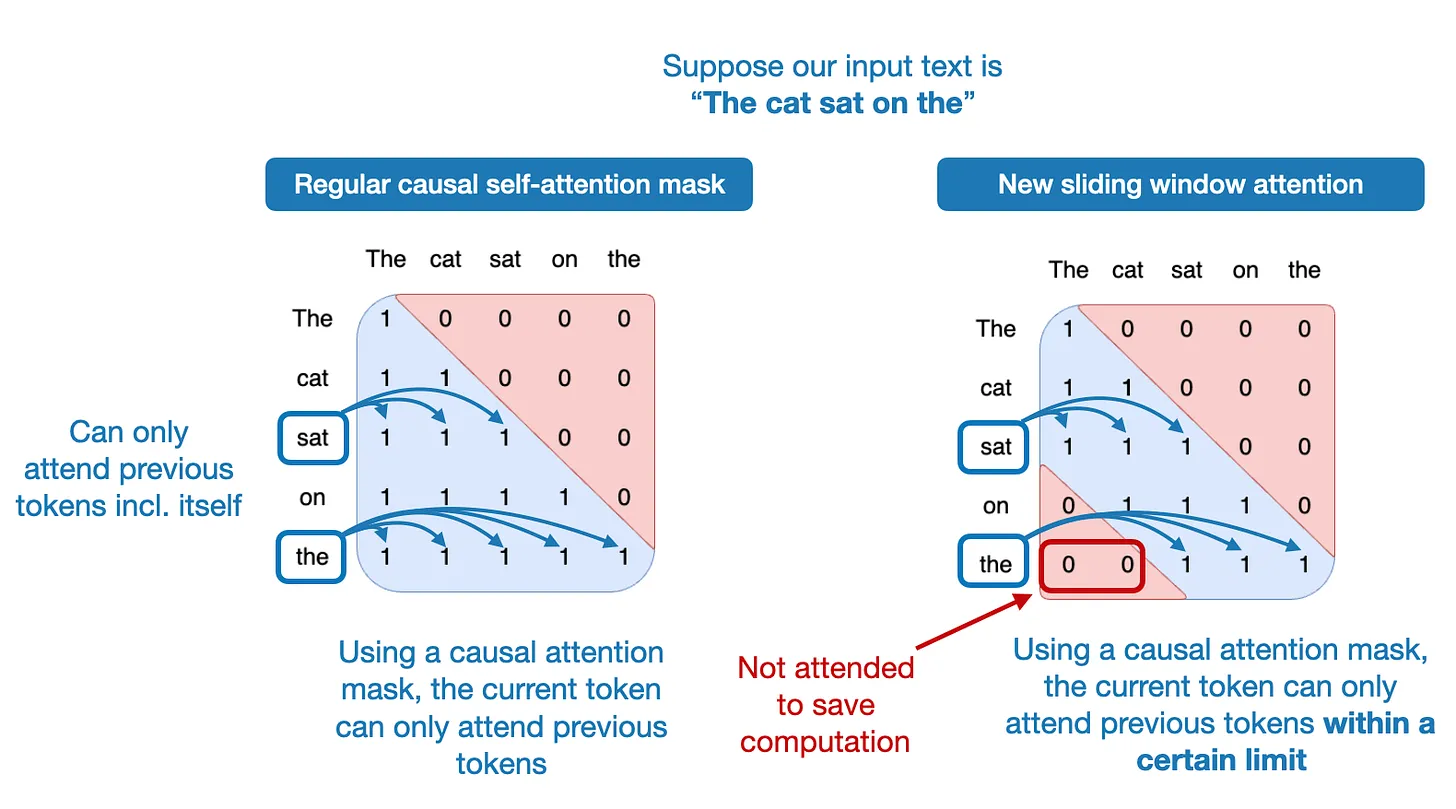
The sliding window attention mechanism is essentially a fixed-sized attention block that allows a current token to attend only a specific number of previous tokens (instead of all previous tokens).
How does this relate to the Attention Sinks paper?
Text embeddings are a critical piece of many pipelines, from search, to RAG, to vector databases and more. Most embedding models are BERT/Transformer-based and typically have short context lengths (e.g., 512). That’s only about two pages of text, but documents can be very long – books, legal cases, TV screenplays, code repositories, etc can be tens... See more
Long-Context Retrieval Models with Monarch Mixer
Nicolay Gerold added

TL;DR
LLMLingua utilizes a compact, well-trained language model (e.g., GPT2-small, LLaMA-7B) to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models (LLMs), achieving up to 20x compression with minimal performance loss.
... See more
LLMLingua utilizes a compact, well-trained language model (e.g., GPT2-small, LLaMA-7B) to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models (LLMs), achieving up to 20x compression with minimal performance loss.
... See more
microsoft • GitHub - microsoft/LLMLingua: To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss.
Nicolay Gerold added
simply accessing LLMs via APIs has limitations. Instead, combining them with other data sources and tools can enable more powerful applications. In this chapter, we will introduce LangChain as a way to overcome LLM limitations and build innovative language-based applications.
Ben Auffarth • Generative AI with LangChain: Build large language model (LLM) apps with Python, ChatGPT, and other LLMs
The first feature is strong meta-attention (attention of attention).
Chade-Meng Tan • Search Inside Yourself: Increase Productivity, Creativity and Happiness [ePub edition]
Self-Attention at a High Level
Don’t be fooled by me throwing around the word “self-attention” like it’s a concept everyone should be familiar with. I had personally never came across the concept until reading the Attention is All You Need paper. Let us distill how it works.
Say the following sentence is an input sentence we want to translate:
” The ... See more
Don’t be fooled by me throwing around the word “self-attention” like it’s a concept everyone should be familiar with. I had personally never came across the concept until reading the Attention is All You Need paper. Let us distill how it works.
Say the following sentence is an input sentence we want to translate:
” The ... See more
Jay Alammar • The Illustrated Transformer
Luc Cheung added