Ajeesh Garg
@ajeesh
Ajeesh Garg
@ajeesh

MAE is less sensitive to outliers but I am still trying to mae as my loss function? Why do you think someone might choose MAE as the loss but still monitor MSE as a metric? What behavior during training might that help catch?
My data distribution is really sparse so as my data distribution is more sparse i choose mae over mse. Basically, it will
... See moreLoss and Loss function
Loss Function notes - mae
Attention and
SAM model

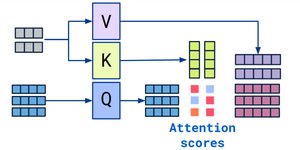
Attention and
Transformers Explained Visually I
Models and
Attention is all you need paper
Transformers and
Vision TransFormers original paper