Sublime
An inspiration engine for ideas
paper - https://t.co/gfiOTVNtfx
writeup - https://t.co/wA1U23uLrh
hash table internals playlist - https://t.co/7HvgfE6yMW
- internal structure of a HashTable
- collision resolution through chaining and open addressing
- collision resolution through... See more
Arpit Bhayanix.com
🔎 𝗦𝗲𝗮𝗿𝗰𝗵-𝗧𝗵𝗮𝘁-𝗛𝗮𝘀𝗵 automates password cracking by scanning popular sites and automatically inputs your hash(es)🔓
» https://t.co/505MIwggGC https://t.co/Ww0Hghgbjz
Pethuraj Mx.com

Data Leakage and deduplication are critical when training LLMs! SemHash is a new, blazingly fast semantic text deduplication library that combines Model2Vec embeddings with ANN-based similarity search through Vicinity, making it possible to deduplicate millions of records in minutes. 👀
TL;DR:
🚀... See more
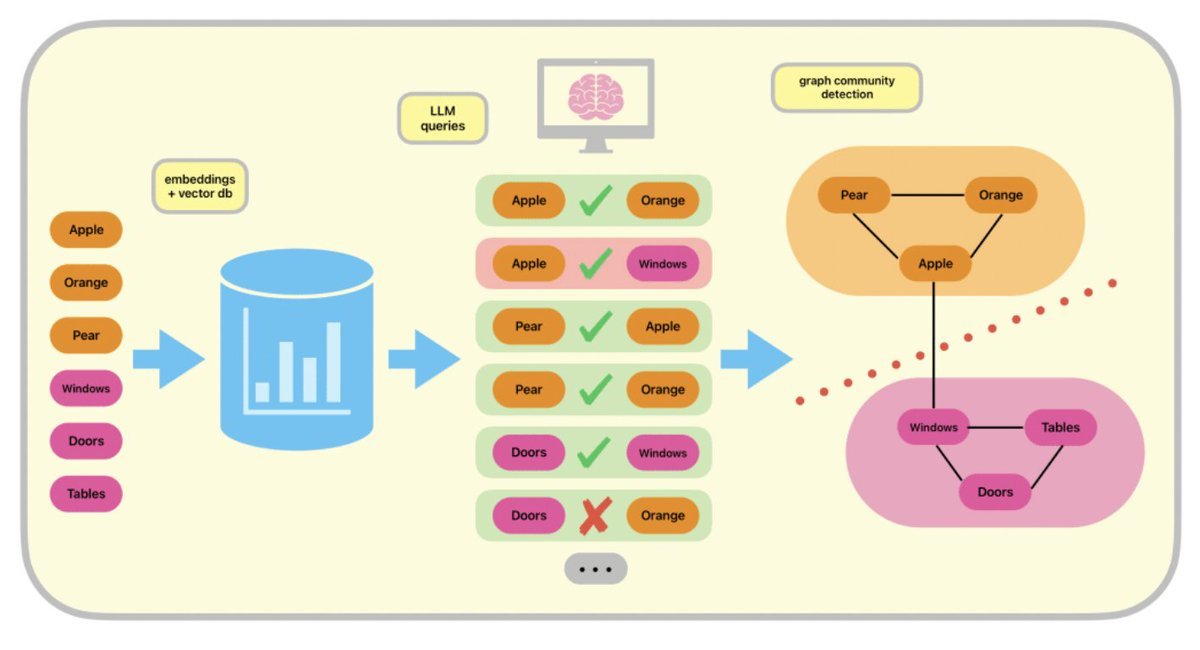
a technique i'm increasingly believing is going to be really useful in large-scale synth data pipelines is the use of graph algorithms to do semantic deduplication
submitted a paper about this a while back, never got around to cleaning it up for arxiv, but it's a neat trick https://t.co/XNVRTWxCSq

Scattered Mixture-of-Experts Implementation
- Presents ScatterMoE, an implementation of Sparse Mixture-of-Experts on GPU
- Enables a higher throughput and lower memory footprint
repo: https://t.co/kJZjY6Q4O7
abs: https://t.co/xxIx1a2vu2 https://t.co/IqWxmNln6W
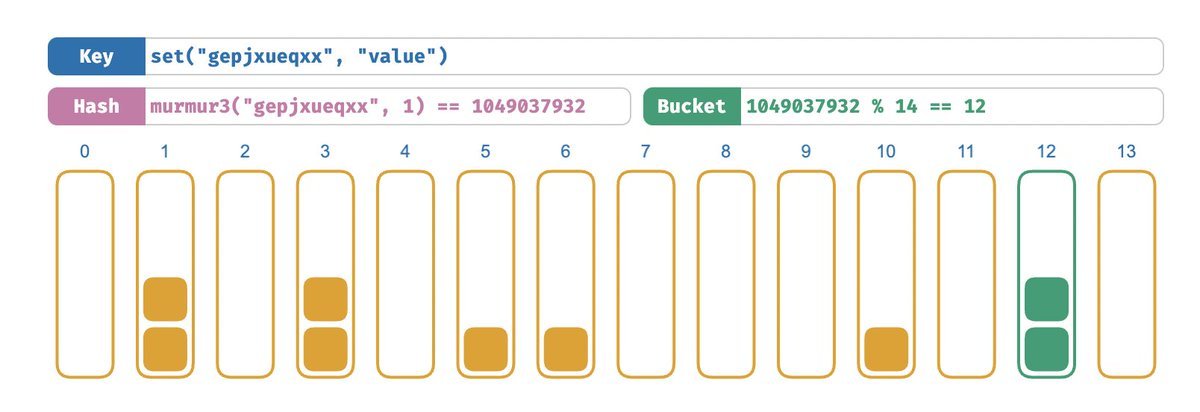
Hashing explained with 🌟best🌟 visualisations
https://t.co/nMknsXDDz6 https://t.co/VGai03cpmw
It’s often beneficial to overlap your chunks to mitigate semantic gaps. My go-to settings are usually a chunk size of 256-304 tokens with 32 tokens of overlap. I’ve found this to work quite well, but your mileage may vary.