Sublime
An inspiration engine for ideas
I built a tool to cut edge AI docker images by 75%. The demo here trims a Flask inference server running @moondream's VLM (vision model).
we trim a VLM inference server from ~400MB to ~100MB (75% reduction *excluding model weights*) while preserving performance. This also works for containerized data jobs, ML tooling,... See more
omkaar in SFx.com
2-5x faster 50% less memory local LLM finetuning
- Manual autograd engine - hand derived backprop steps.
- 2x to 5x faster than QLoRA. 50% less memory usage.
- All kernels written in OpenAI's Triton language.
- 0% loss in accuracy - no approximation methods - all exact.
- No change of hardware necessary. Supports NVIDIA GPUs since 2018+. Minimum CUDA Compute
unslothai • GitHub - unslothai/unsloth: 5X faster 50% less memory LLM finetuning
DiscoLM German 7B v1 - GGUF
Model creator: Disco Research
Original model: DiscoLM German 7B v1
Description
This repo contains GGUF format model files for Disco Research's DiscoLM German 7B v1.
These files were quantised using hardware kindly provided by Massed Compute.
About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023.... See more
Model creator: Disco Research
Original model: DiscoLM German 7B v1
Description
This repo contains GGUF format model files for Disco Research's DiscoLM German 7B v1.
These files were quantised using hardware kindly provided by Massed Compute.
About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023.... See more
TheBloke/DiscoLM_German_7b_v1-GGUF · Hugging Face
V7 Go | Automate Tasks at Scale with LLMs & Gen AI Workflows
v7labs.com
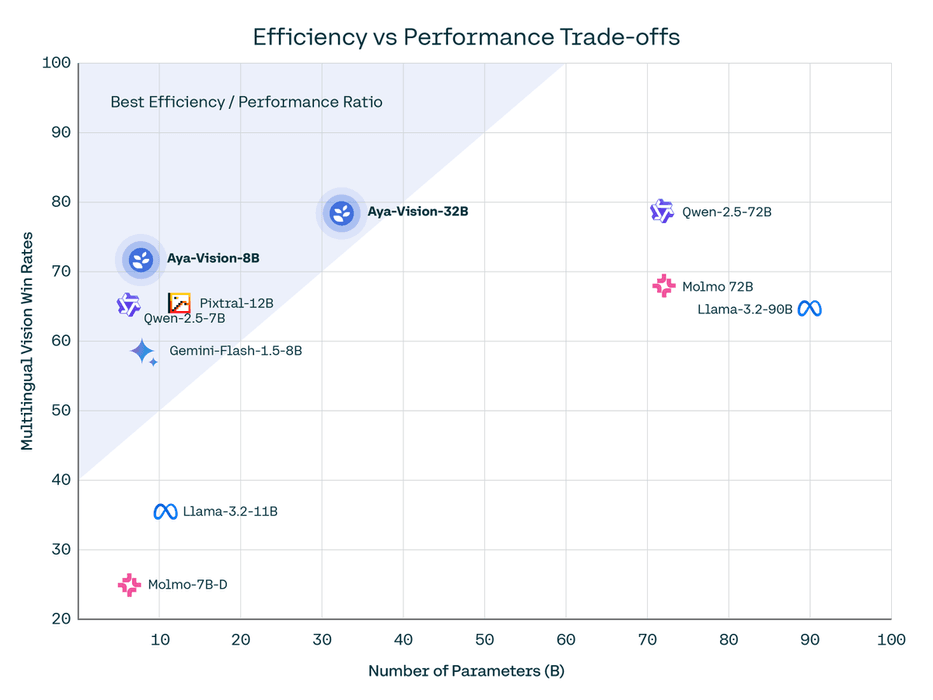
LFGG! Cohere just dropped Aya Vision 32B and 8B - beats Llama 3.2 90B Vision and Gemini Flash 🔥
> 8B Model: Best-in-class for its parameter size, outperforming competitors by up to 81% win rates
> 32B Model: Outperforms models 2x its size, achieving 49%-72% win... See more
slowllama
Fine-tune Llama2 and CodeLLama models, including 70B/35B on Apple M1/M2 devices (for example, Macbook Air or Mac Mini) or consumer nVidia GPUs.
slowllama is not using any quantization. Instead, it offloads parts of model to SSD or main memory on both forward/backward passes. In contrast with training large models from scratch... See more
Fine-tune Llama2 and CodeLLama models, including 70B/35B on Apple M1/M2 devices (for example, Macbook Air or Mac Mini) or consumer nVidia GPUs.
slowllama is not using any quantization. Instead, it offloads parts of model to SSD or main memory on both forward/backward passes. In contrast with training large models from scratch... See more