Sublime
An inspiration engine for ideas
Let's reverse engineer the phenomenal Tesla Optimus. No insider info, just my own analysis. Long read:
1. The smooth hand movements are almost certainly trained by imitation learning ("behavior cloning") from human operators. The alternative is reinforcement learning in simulation, but that typically leads to jittery m... See more
Jim Fanx.com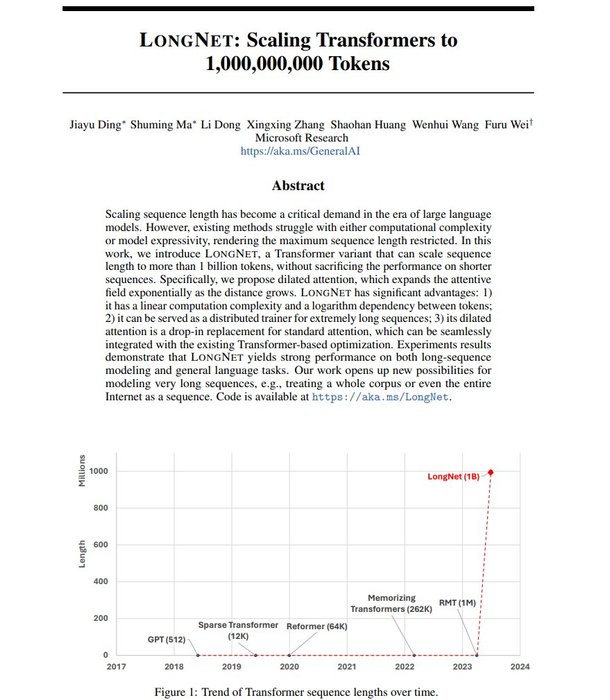
LongNet: Scaling Transformers to 1,000,000,000 Tokens
Presents LONGNET, a Transformer variant that can scale sequence length to more than 1 billion tokens, without sacrificing the performance on shorter sequences
abs: https://t.co/5rf4tcVDuk
repo:... See more



Introducing 1.58bit DeepSeek-R1 GGUFs! 🐋
DeepSeek-R1 can now run in 1.58-bit, while being fully functional. We shrank the 671B parameter model from 720GB to just 131GB - a 80% size reduction.
Naively quantizing all layers breaks the model entirely, causing endless loops & gibberish outputs.... See more
deep learning
Prashanth Narayan and • 4 cards

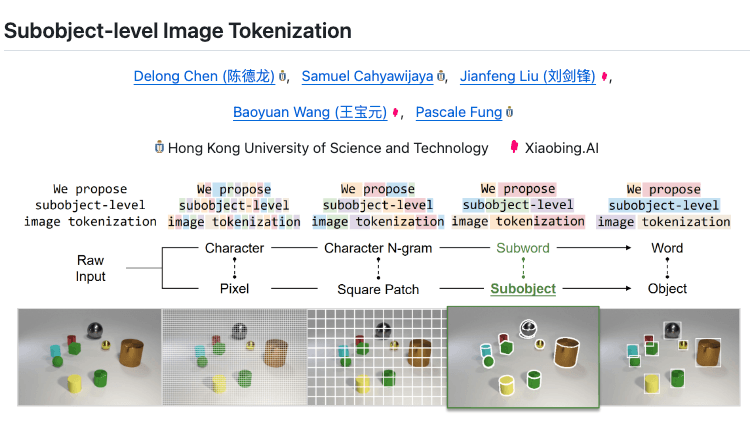
Subobject-level Image Tokenization
Transformer-based vision models typically tokenize images into fixed-size square patches as input units, which lacks the adaptability to image content and overlooks the inherent pixel grouping structure. Inspired by the subword tokenization widely adopted in language models, we propose... See more

FlexiViT: One Model for All Patch Sizes
Shows that randomizing the patch size at training leads allows the model to performs well across various patch sizes, making it possible to tailor the model to different compute budgets at deployment.
https://t.co/FCsYIi3fgN... See more