Sublime
An inspiration engine for ideas
A matter of choice: People and possibilities in the age of AI
The 2025 Human Development Report explores the intersection of artificial intelligence and human development, emphasizing the importance of people's choices in shaping equitable outcomes amid technological advancements.
hdr.undp.orgPDFs are satan’s file format.
Almost everyone that builds RAG needs to deal with them - and it sucks.
Solutions on the market are either too slow, too expensive or not OSS.
It should be easier. Which is why we’re open sourcing https://t.co/0gCZxzbkWu
Ishaan Kapoorx.comI taught an LLM to optimize proteins. It proposed a better carbon capture enzyme.
Introducing Pro-1, an 8b param reasoning model trained using GRPO towards a physics based reward function for protein stability.
It takes in a protein sequence + text description + previous experimental... See more
Michael Hlax.comHow to Create Llama3 RAG Application using PhiData? (PDF Compatible)
📜 PDF Data Handling
🔗 URL Data
🌐 @GroqInc & @ollama Integration (100% Private)
⚙️ Automatic Embedding
🗄️ Save in @pgvector Database
🌍 @streamlit User Interface
🔄... See more
Mervin Praisonx.com
Very useful for LLM Prompting. This will pack your entire repository into a single, LLM-friendly file with one command.
Needed for feeding your entire codebase to Claude/ChatGPT etc.
To pack a specific directory just run
`repopack path/to/directory`... See more
Interesting Github Repo
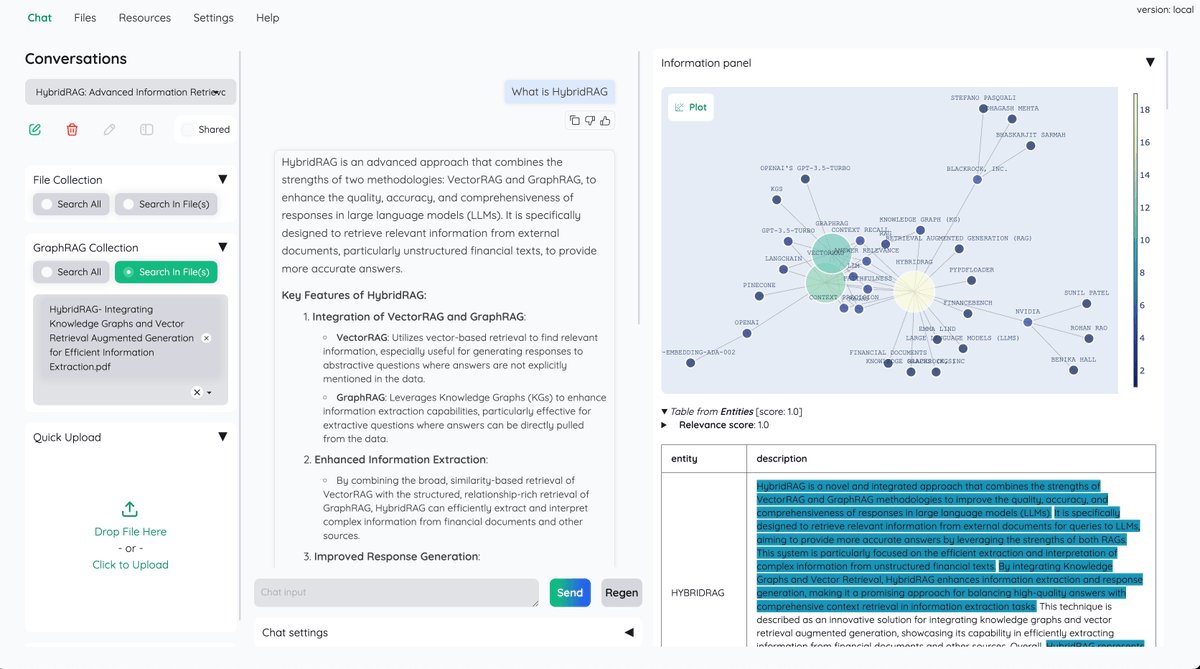
An open-source clean & customizable RAG UI for chatting with your documents. https://t.co/OfC9dNgPAh
Mercer_Pub 248
The study describes the development of a continuous evolution system to engineer small degron tags that can be inserted into endogenous genes and selectively degrade proteins using specific small molecules.
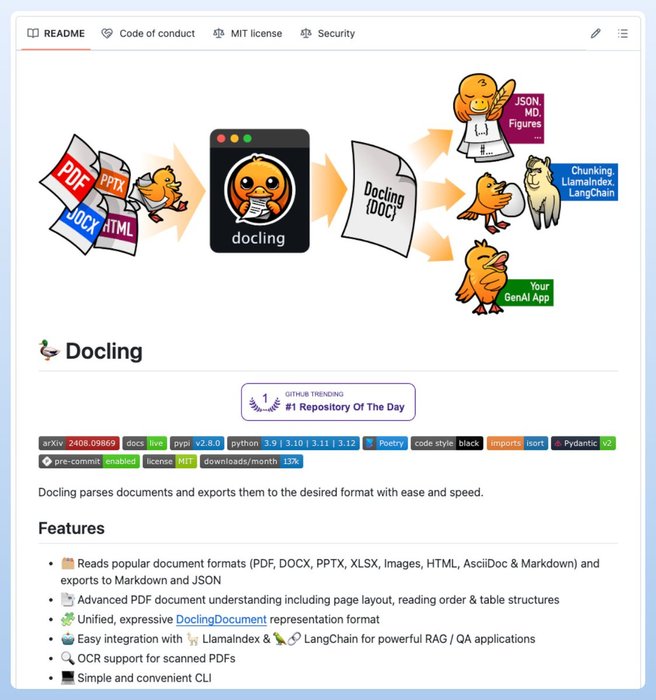
LinkRAG engine that just works for complex real-world documents.
It can extract knowledge from unlimited tokens across ANY data format - Word docs, Excel sheets, PDFs, and even scanned copies.
And it's 100% Opensource. https://t.co/DZqBliORez
Shubham Saboox.com