Sublime
An inspiration engine for ideas

PydanticAI: Build production-grade Agentic AI apps in pure Python!
PydanticAI offers the same elegance and ease of use as FastAPI, now extending that experience to building production-grade LLM applications.
Why PydanticAI?
🔌 Model-agnostic
✅ Type-... See more
The quant finance starter pack:
Markets:
• Economics
• Microstructure
Stats:
• Probability
• Time series analysis
Math:
• Calculus
• L... See more
PyQuant News 🐍x.com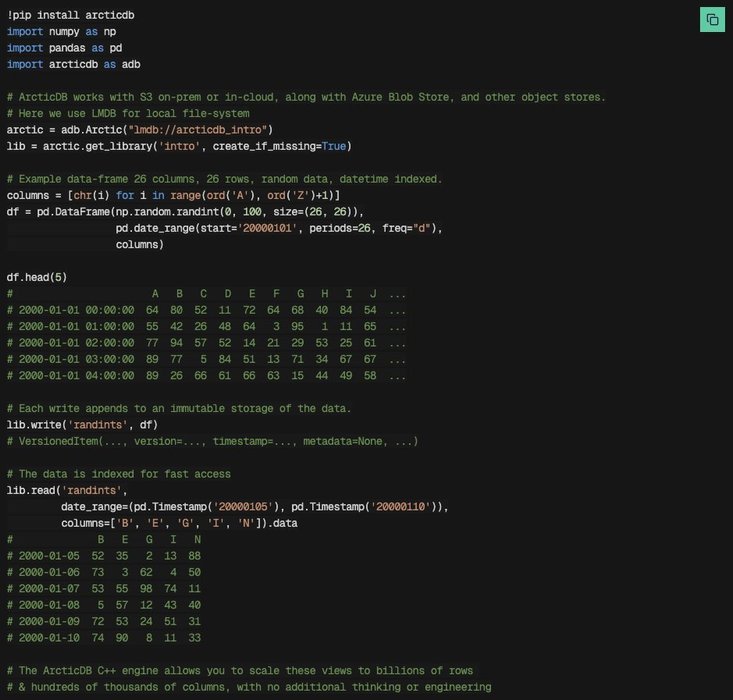
How to process billions of rows in seconds?
ArcticDB.
• DataFrame database
• Proven petabyte-scale
• Used by hedge funds and Bloomberg
And it's free: https://t.co/8qPLIxZyFo
Legacy Quants:
• Think coding is for geeks
• Constrained by Excel '97
• Hide their "secrets"
Modern Quants:
• Knows coding is the future
• Curious to try new things
• Builds in public
___LINEBR... See more
PyQuant News 🐍x.com

The memory in Transformers grows linearly with the sequence length at inference time.
In SSMs it is constant, but often at the expense of performance.
We introduce Dynamic Memory Compression (DMC) where we retrofit LLMs to compress their KV cache while preserving performance and vastly surpa... See more