Sublime
An inspiration engine for ideas

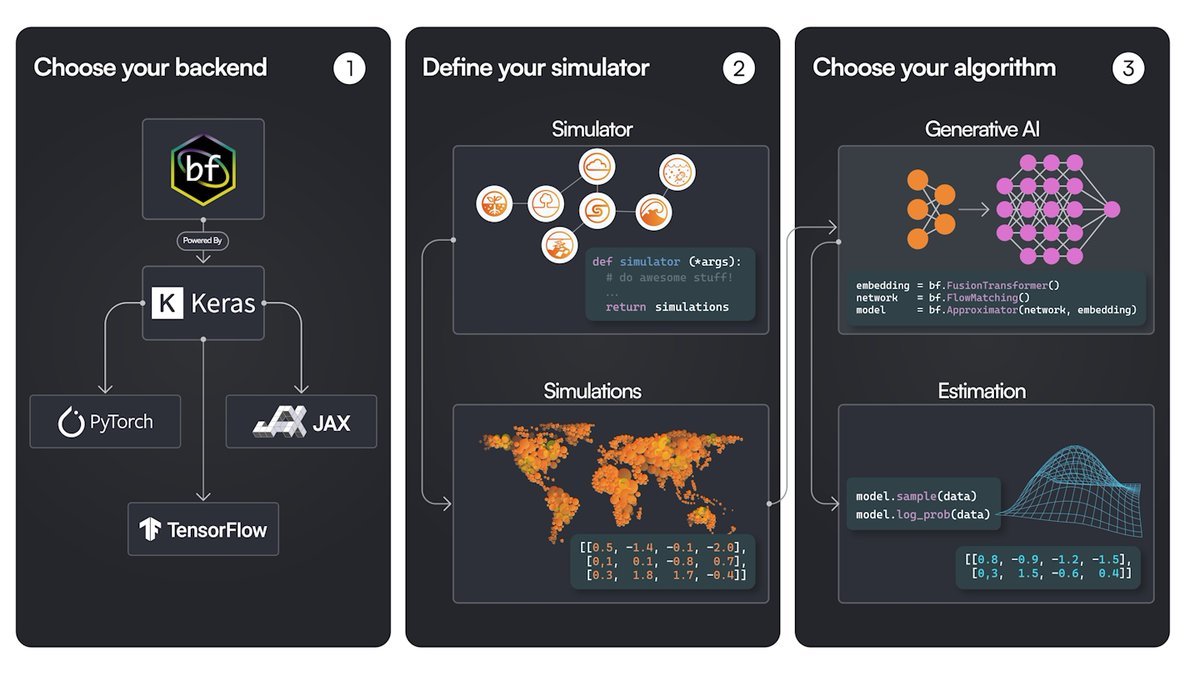
BayesFlow 2.0, a Python package for amortized Bayesian inference, is now powered by Keras 3, with support for JAX, PyTorch, and TF.
Great tool for statistical inference fueled by recent advances in generative AI and Bayesian inference.
(Links in next tweet) https://t.co/Gp1R3ohP3U

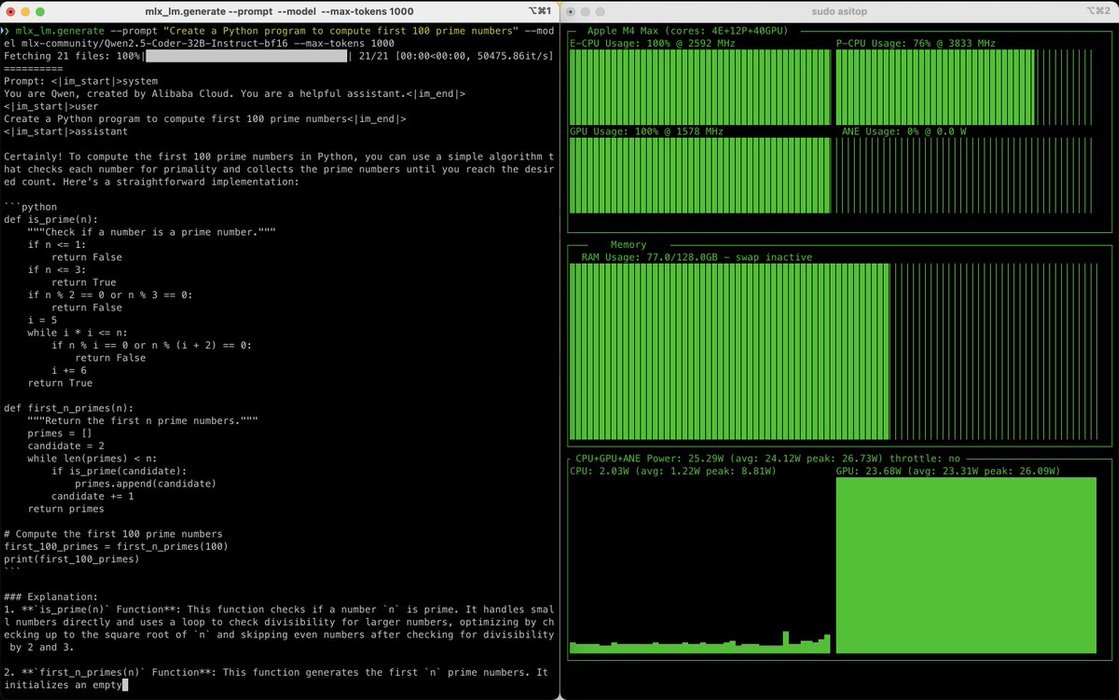
Qwen2.5 Coder 32B running on M4 Max on Apple MLX.
Prompt: Create a Python program to compute first 100 prime numbers
Results (Prompt t/s - Generation t/s - RAM):
- q4: P 102.40 - G 24.62 - 18.64GB
- q8: P 115.50 - G 13.73 - 35.02GB
- bf16: P 90.65 - G 7.56 - 65.67 GB... See more
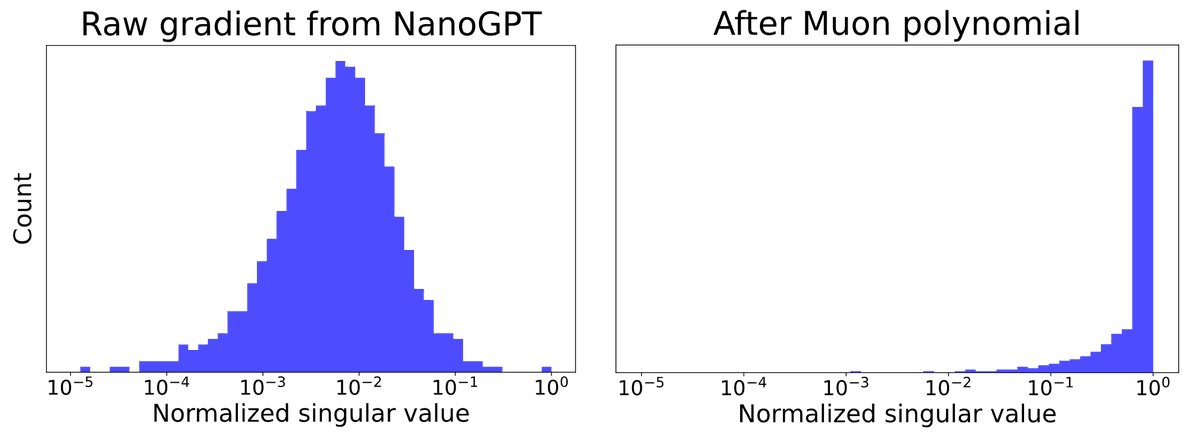
[1/6] Curious about Muon, but not sure where to start? I wrote a 3-part blog series called “Understanding Muon” designed to get you up to speed—with The Matrix references, annotated source code, and thoughts on where Muon might be going.




ML News of the day🚨
Is it hard to keep up with all the amazing things happening in the ML ecosystem? Here is a quick summary of yesterday's top 5 ML releases - from small models to video generation!🚀
1. Microsoft releases Orca 2
Orca 2 goal is to explore small LLM capabilities.... See more
Omar Sansevierox.com