Sublime
An inspiration engine for ideas
RedPajama-V2 is an open dataset for training large language models. The dataset includes over 100B text
documents coming from 84 CommonCrawl snapshots and processed using
the CCNet pipeline. Out of these, there are 30B documents in the corpus
that additionally come with quality signals. In addition, we also provide the ids of duplicated documents... See more
documents coming from 84 CommonCrawl snapshots and processed using
the CCNet pipeline. Out of these, there are 30B documents in the corpus
that additionally come with quality signals. In addition, we also provide the ids of duplicated documents... See more
togethercomputer/RedPajama-Data-V2 · Datasets at Hugging Face
Anthropic/EconomicIndex · Datasets at Hugging Face
huggingface.co

The #tidyplots paper is now published in @iMetaScience 🎉🥳🔥
Whenever you use tidyplots in your published work, consider citing https://t.co/n58lCO3Epv 🙏
#rstats #dataviz #phd https://t.co/oJqvscdv1M
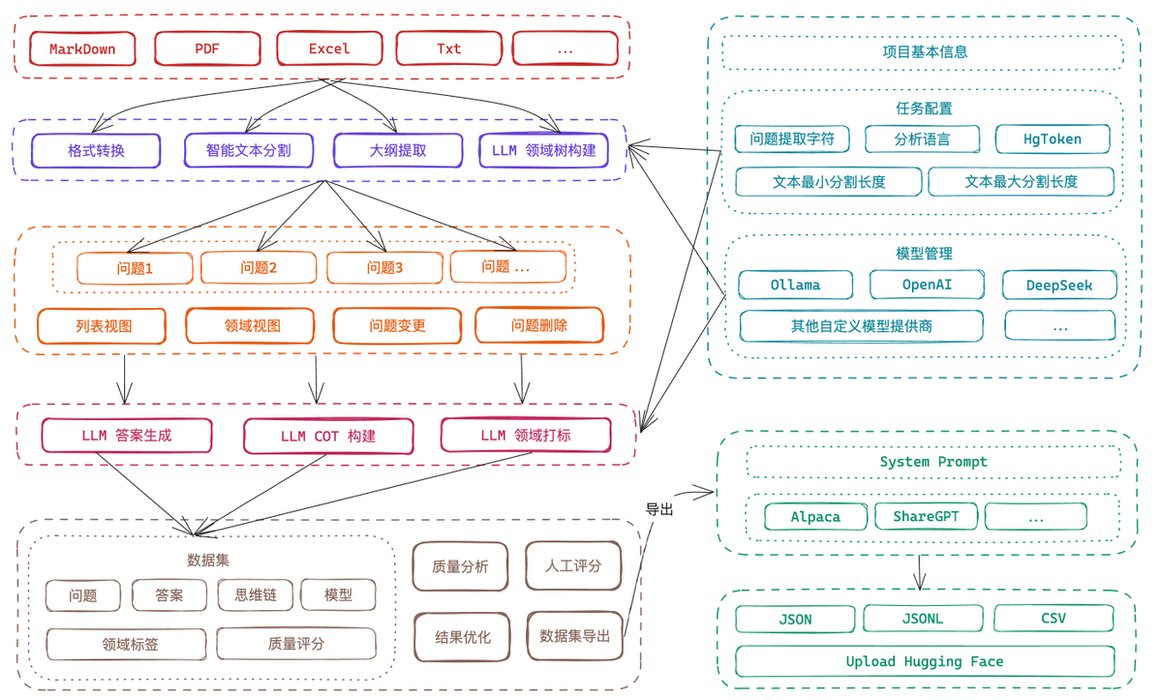
一个简单易用的大模型微调数据集创建工具:Easy DataSet。
提供了直观的界面,上传文件,智能分割内容,生成问题,并为模型微调生成高质量的训练数据。
GitHub:https://t.co/s36Y3sHhm9
此外,还支持导出 Alpaca、JSON 等多种格式数据集,同时兼容所有遵循 OpenAI 格式的 LLM API。
提供 Windows、MacOS 和 Linux 安装包下载,开箱即用,也支持 Docker 部署和 NPM 安装。
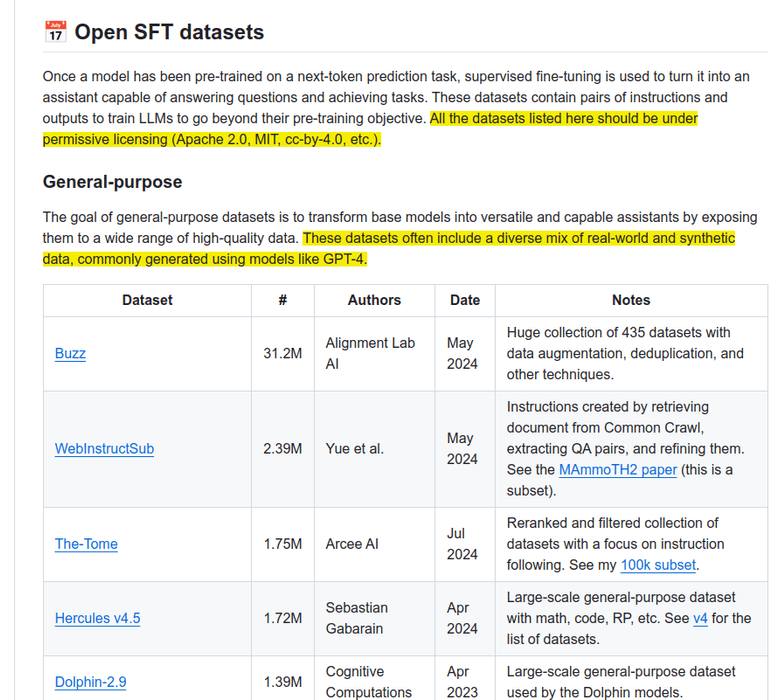
This Github has a very wide collection of High-quality datasets, tools, and concepts for LLM fine-tuning.
All the datasets listed here should be under permissive licensing (Apache 2.0, MIT, cc-by-4.0, etc.).
Categorized into segments like Math & Logic, Code, Conversation & Role-Play, Agent &... See more




Our first batch of four diffusion models, along with super basic CLIP guided inference code, is out! https://t.co/OUOMleFolF The models are:
Danbooru SFW 128x128
ImageNet 128x128
WikiArt 128x128
WikiArt 256x256
No Colab yet but soon!... See more

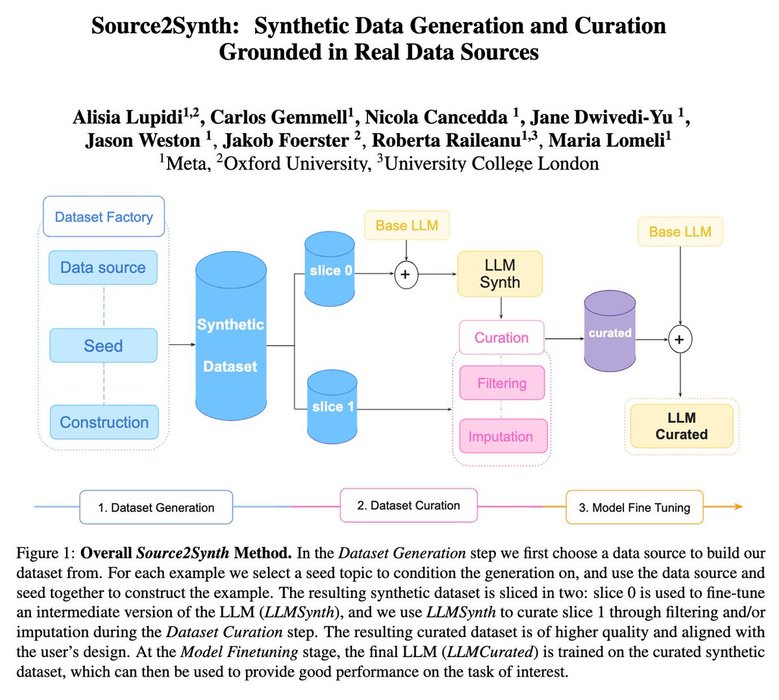
🚨New paper: Source2Synth🚨
- Generates synthetic examples grounded in real data
- Curation step makes data high quality based on answerability
- Improves performance on two challenging domains: Multi-hop QA and using tools: SQL for tabular QA
https://t.co/4uggsiniIv
🧵(1/4)... See more

Yesterday I reviewed ~30 open datasets and there was a spectrum of quality. While I don't believe all data need to be identically formatted, I do think data should meet these standards and include thorough documentation (e.g., a data dictionary and project summary). https://t.co/0Qe1ASmoEk