Sublime
An inspiration engine for ideas
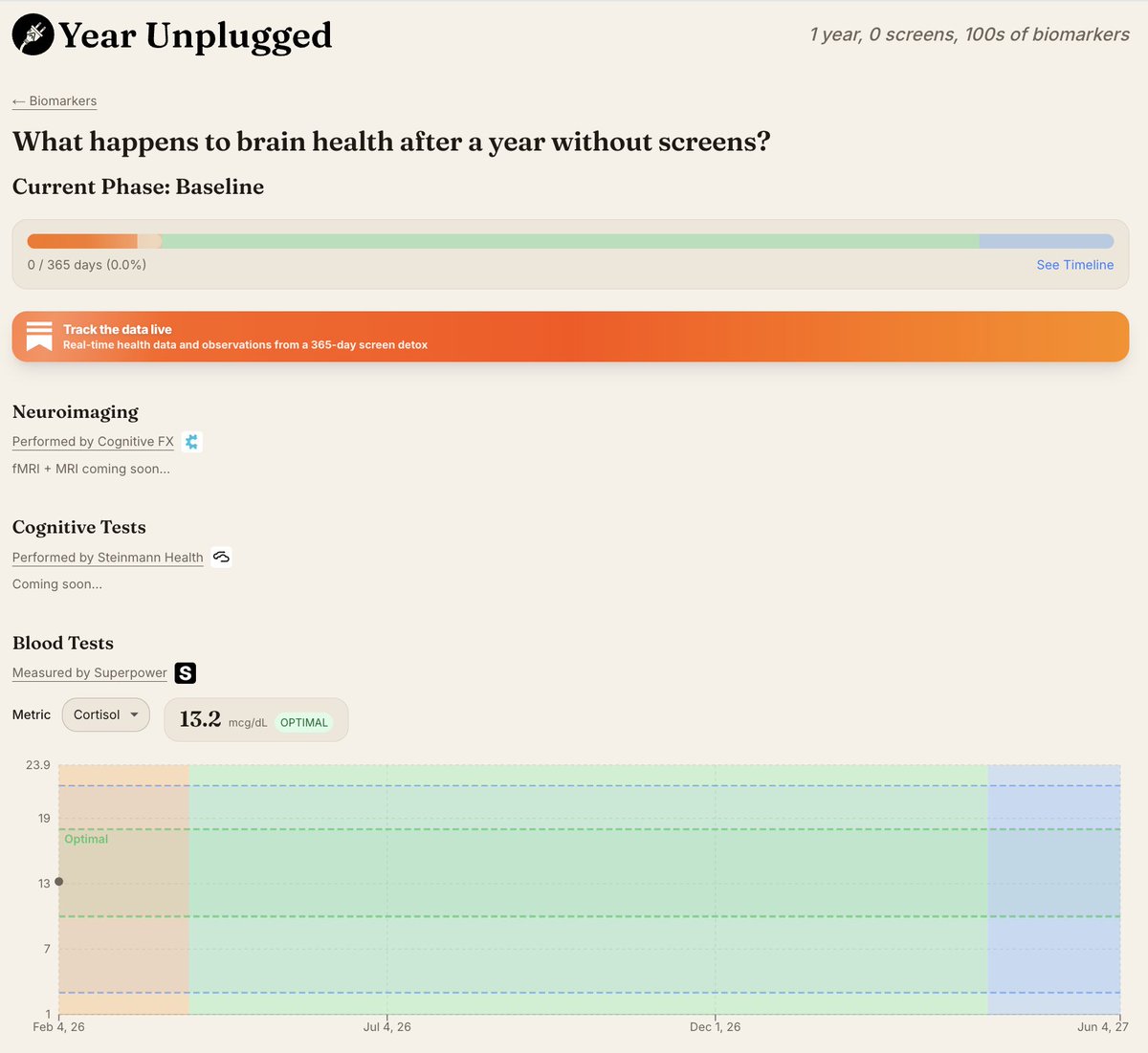
Today I am scanning my brain before I spend a year without screens
Doctors expect brain function to change, but whether the structure itself changes, nobody seems to know
All the data will be public: baseline, 6-month, and 12-month scans included https://t.co/X09rYf79Fb
Writing is a task that takes both objective and subjective intelligence. LLMs ace the objective parts the same way they ace every test; you can’t fault their grammar, semantics, or syntax. But good writing requires an additional bit of juju that makes the prose live and breathe, a light on the inside that can’t be quantified or checklisted. And... See more
Infinite midwit
to be truly radical is to make hope possible rather than despair convincing.
kyla scanlon • The Ozempicization of Everything


:)))
instagram.comKevin Lynch What Time Is This Place
An environment that facilitates recalling and learning is a way of linking the living moment to a wide span of time. Being alive is being awake in the present, secure in our ability to continue but alert to the new things that come streaming by. We feel our own rhythm, and feel also that it is part of the rhythm
... See more