Sublime
An inspiration engine for ideas

Meta 🤝 Apple
Llama 4 + Apple Silicon is a match made in heaven.
Here's why: Like DeepSeek V3/R1, all of the new Llama 4 variants are massive sparse MoE models. They have a massive amount of parameters, but only a small number of those are active each time a token is generated. We don't know... See more


In our current project we are pushing GPU to the max.
40k instances. 20M tris. 25fps on M1 and 60fps on RTX3900. WebGL baby!
Hi-res screenshot in next tweet. https://t.co/ZyYm0TWA99
Marcin Ignacx.com
DeepSeek R1 671B running on 2 M2 Ultras faster than reading speed.
Getting close to open-source O1, at home, on consumer hardware.
With mlx.distributed and mlx-lm, 3-bit quantization (~4 bpw) https://t.co/RnkYxwZG3c
Awni Hannunx.com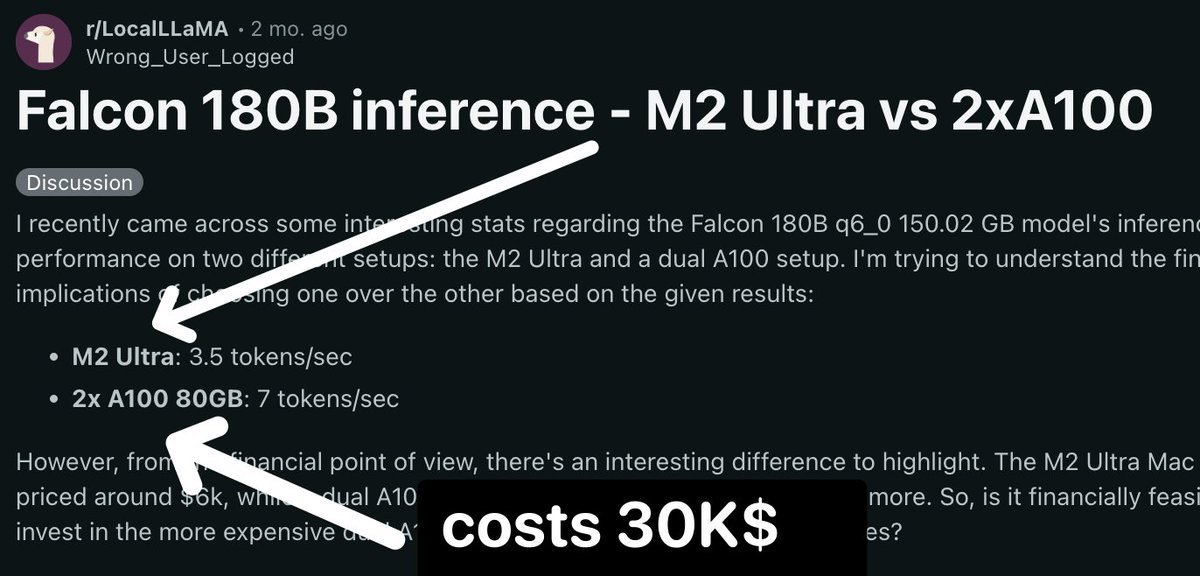
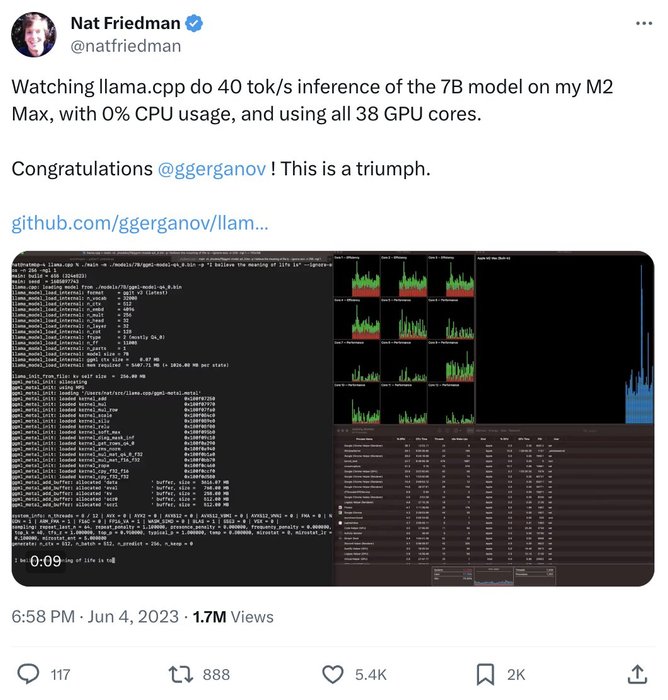
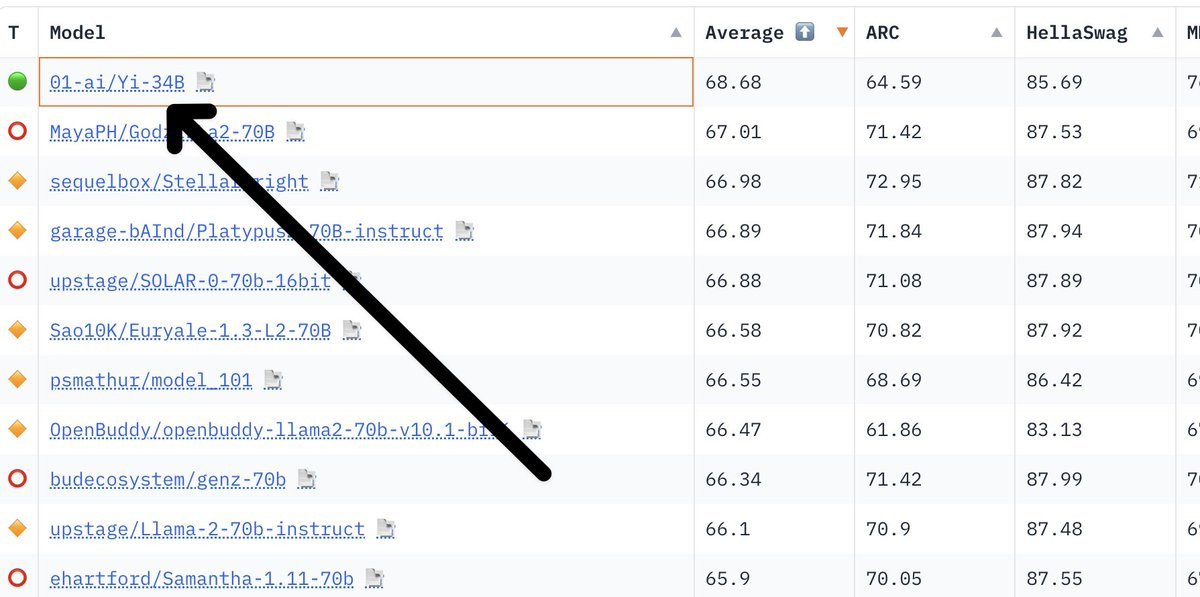
People are just starting to realize the power of Local LLMs
Especially with new Apple chips. It's a game-changer
Let me show you:
Falcon is 180B LLM. It is the size of GPT3.
How fast would it run on your Mac?
Apple M3 Max: 3.5... See more




Some major and primarily positive announcements for @Intel, some related to the recent BoD meeting. Thanks @pgelsinger for the time to walk me through this. Here's my take (not PG or $INTC):
@AWSCloud & Intel multi-year wafer, Xeon 6 co-design:
-multi-year, multi $B “framework” for product &... See more