Sublime
An inspiration engine for ideas
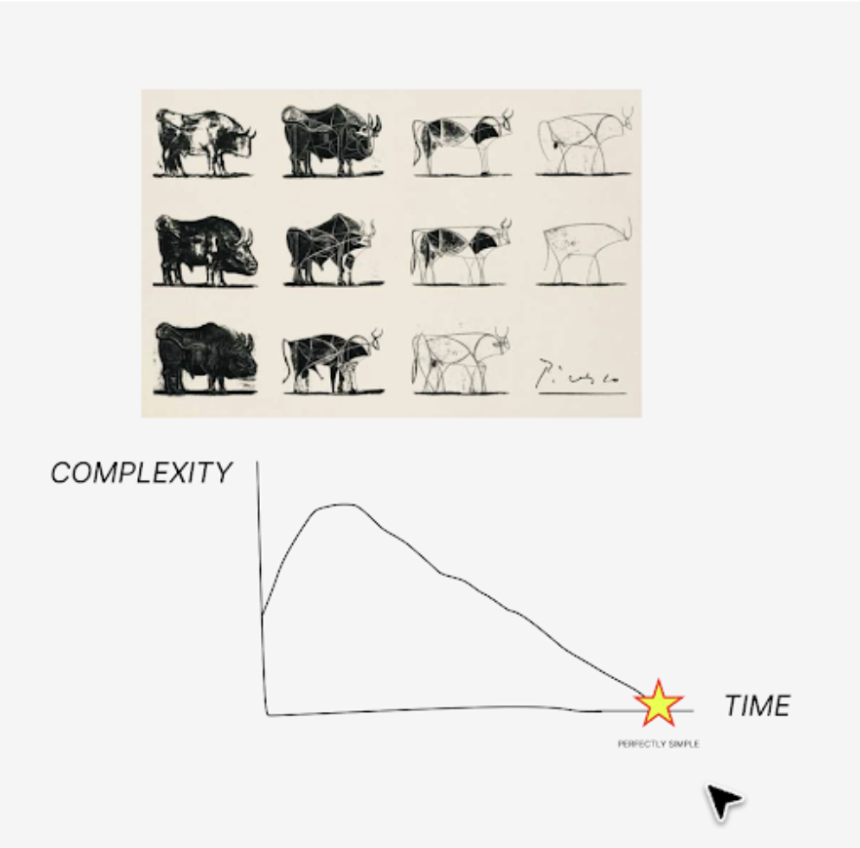
If everyone is busy making everything,
how can anyone perfect anything?
We start to confuse convenience with joy.
Abundance with choice.
Designing something requires focus.
The first thing we ask is:
What do we want people to feel?
Delight.
Surprise.
Love.
Connection.
Then we begin to craft around our intention.
It takes time.
There are a thousand no’s for... See more
how can anyone perfect anything?
We start to confuse convenience with joy.
Abundance with choice.
Designing something requires focus.
The first thing we ask is:
What do we want people to feel?
Delight.
Surprise.
Love.
Connection.
Then we begin to craft around our intention.
It takes time.
There are a thousand no’s for... See more
Apple, “Intention” | Insights and Inspiration from 50+ Great Examples


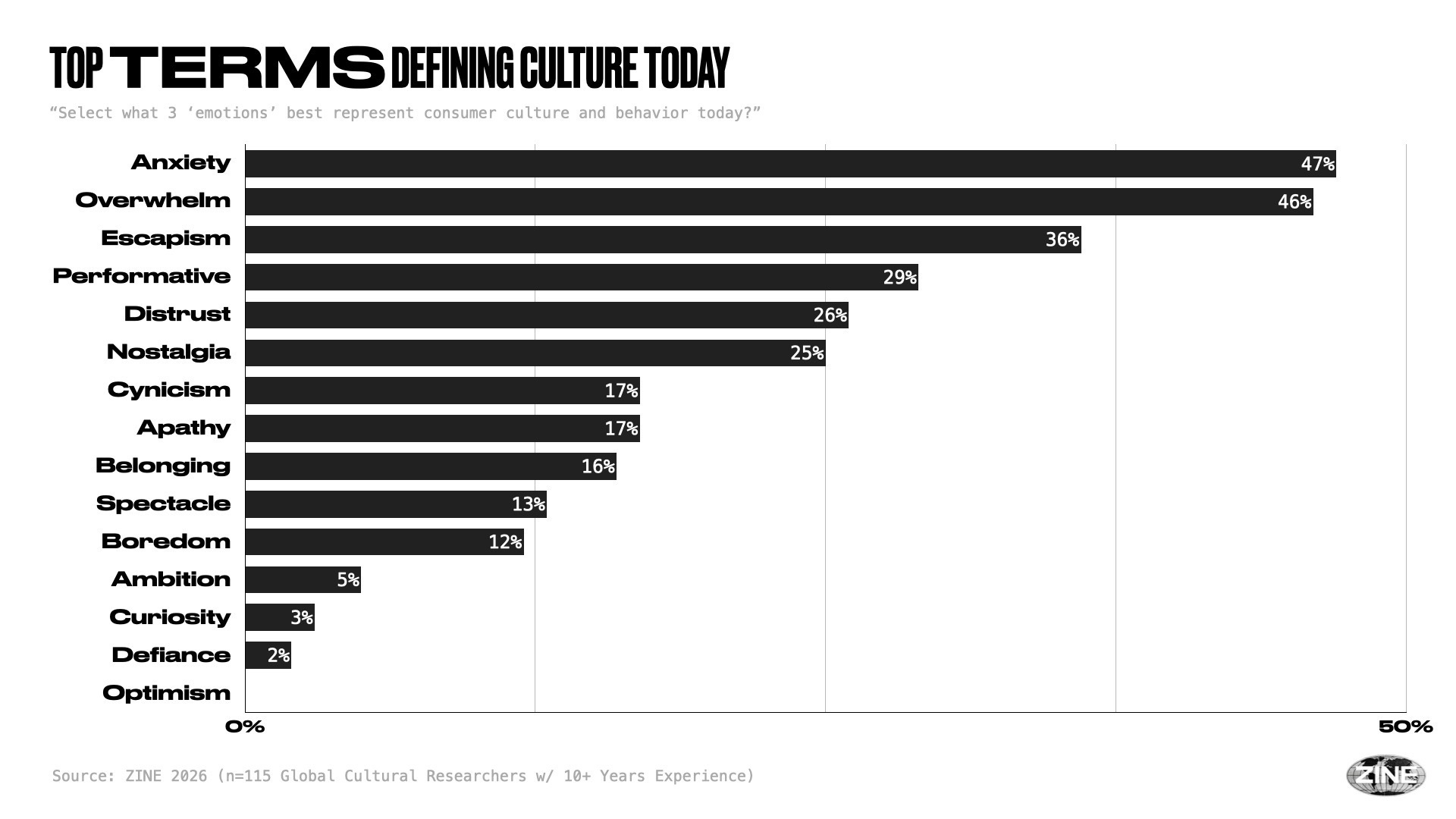

Idle agents will turn us into even more of productivity monsters
Every industrial leap promised more leisure. Instead, it raised the baseline.
Factories did not shorten ambition. And as agents run 24/7, time becomes even more yield-bearing.
So AI may mean we’ll have more time for “less mundane things”, but markets will likely turn that into higher