Sublime
An inspiration engine for ideas
One consistent tension I’m navigating:
The pull to be at the vanguard of technology (learn Claude Code, install OpenClaw, vibe code everything!) and hurriedly experiment and drop ~$50 worth of credits on a project while asking Claude for step by step instructions like I’m disarming a bomb (“which wire,... See more
Camilo Moreno-Salamancasubstack.comGRIMES: I think that’s the huge privilege of an artist. Nothing can hurt you because every bit of pain you’ve lived allows you to make great things.
“This Is A Bigger Deal Than Jesus”: The Return of Grimes
What is love? Ask 19 geniuses. Get 19 answers.
�• Plato: It's remembering a soul.
• Freud: It's desire in disguise.
• Buddha: It's letting go.
• Nietzsche: It's dangerous weakness.
• Aristotle: It's one soul in two bodies.
• Kafka: It's a wound that... See more
Unfilteredx.com
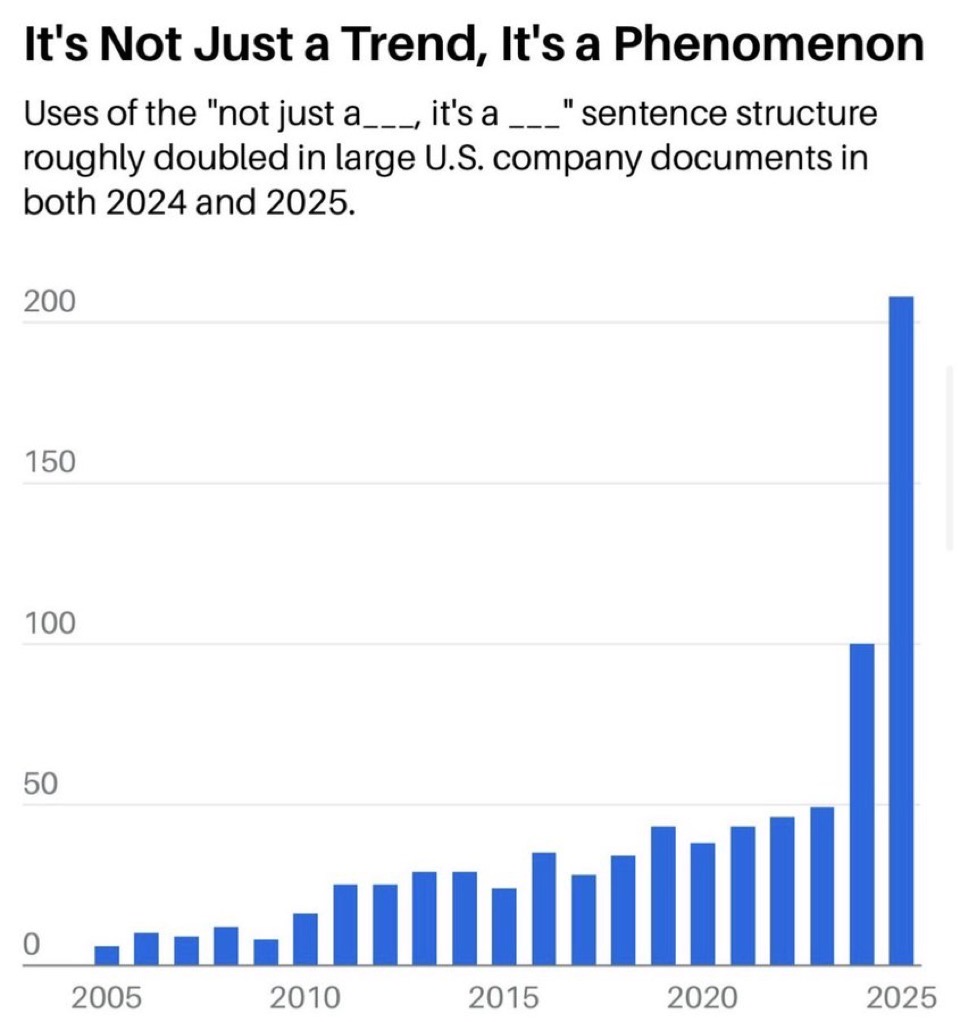
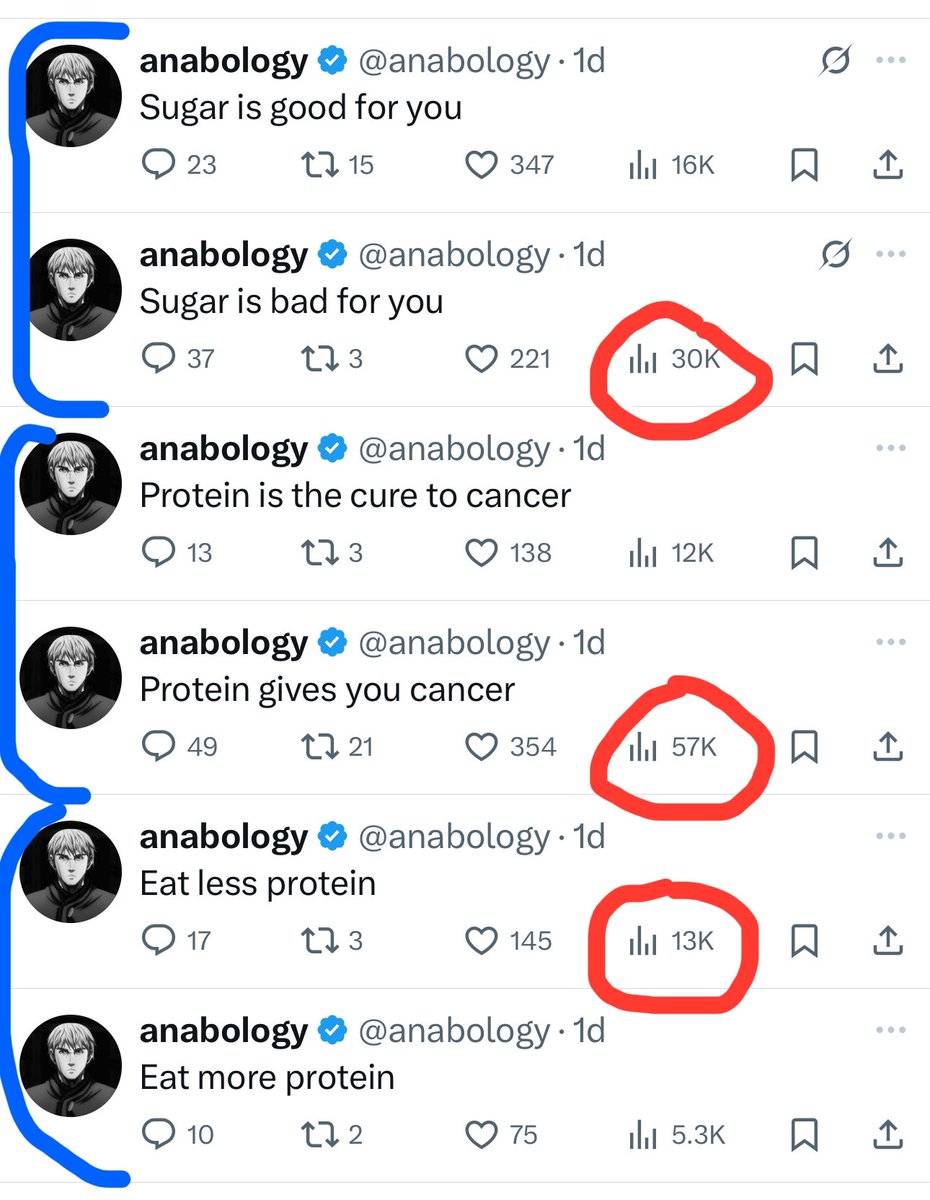
Similarly, I think people need to ask themselves – and it might be easier if we ask each other – What do you really want to be doing? How did you fall in love in the first place? People start optimizing for things like “hm, if I did this I would get 5% more traffic” or “I would get to the next follower milestone” I think because it’s visible, and... See more
Anna Dorothea Ker • "People First" - Making Tech Work for You

Distinguishing healthy self-acknowledgment from destructive shame that hijacks our inner narrative and blocks love, creativity.
TRANSCRIPT
Very good. So I think acknowledging the flaws is critical, critical, always. Acknowledging my humanness, my vulnerability, my frailty, the fact that I make mistakes, the fact that I fall, I stumble, and I sometimes have a very weak moment. And even internally, the fact that even if nobody sees it, I'm struggling with something that may be very,
... See more