Sublime
An inspiration engine for ideas
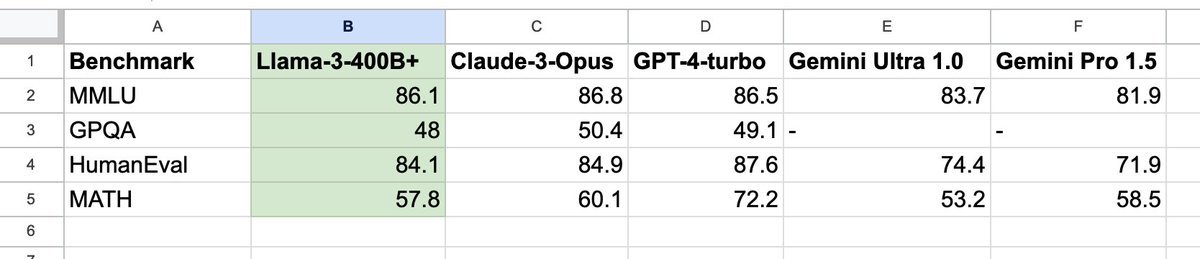
The upcoming Llama-3-400B+ will mark the watershed moment that the community gains open-weight access to a GPT-4-class model. It will change the calculus for many research efforts and grassroot startups. I pulled the numbers on Claude 3 Opus, GPT-4-2024-04-09, and Gemini.
Llama-3-400B is still training and will... See more
GPT-4.5 is ready!
good news: it is the first model that feels like talking to a thoughtful person to me. i have had several moments where i've sat back in my chair and been astonished at getting actually good advice from an AI.
bad news: it is a giant, expensive model. we really wanted to... See more
Sam Altmanx.comI'm excited to announce the release of GPT4All, a 7B param language model finetuned from a curated set of 400k GPT-Turbo-3.5 assistant-style generation.
We release💰800k data samples💰 for anyone to build upon and a model you can run on your laptop!
Real-time Sampling on M1 Mac https://t.co/HgEgnlwYV8
Andriy Mulyarx.com
gpt5 officially lands in july and this thing isn't just another upgrade. it's legit agi. like, artificial general intelligence. no cap. openai's been lowkey cooking this beast for months, and it's finally here.
first off, gpt5 isn't just a language model anymore. it's a unified neural architecture. text, code, images,... See more
🍓🍓🍓x.comOpenAI has finally released GPT OSS 20B!!
This is probably the most powerful model you can run locally on a laptop.
→ Only 3.6B active parameters
→ Adjustable "Reasoning Effort"
→ Works with 16GB of RAM!
Quick steps to use it 100% free... See more
Paul Couvertx.com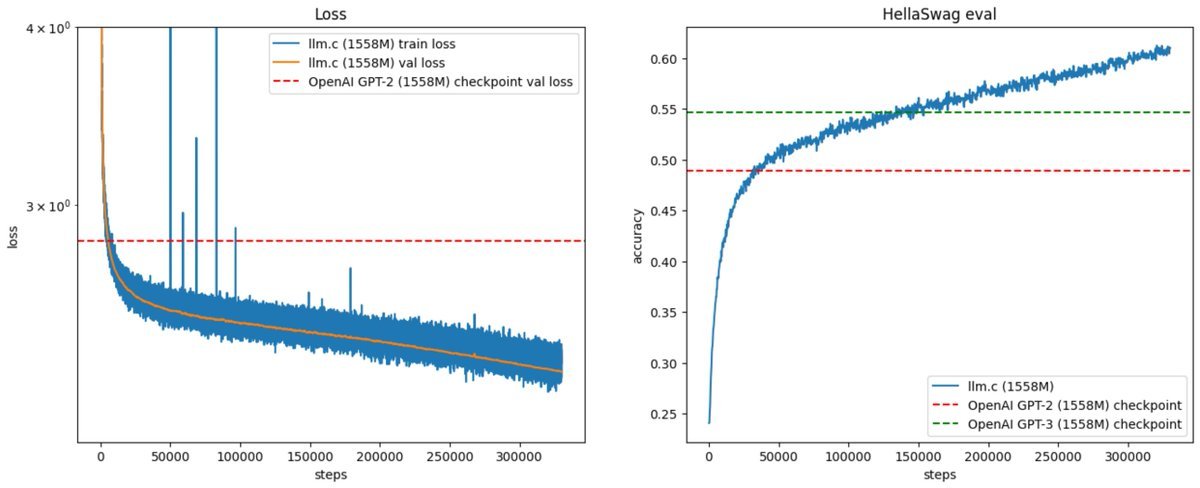
In 2019, OpenAI announced GPT-2 with this post:
https://t.co/jjP8IXmu8D
Today (~5 years later) you can train your own for ~$672, running on one 8XH100 GPU node for 24 hours. Our latest llm.c post gives the walkthrough in some... See more
GPT 4.5 + interactive comparison :)
Today marks the release of GPT4.5 by OpenAI. I've been looking forward to this for ~2 years, ever since GPT4 was released, because this release offers a qualitative measurement of the slope of improvement you get out of scaling pretraining compute (i.e. simply training a bigger... See more
Andrej Karpathyx.com