Sublime
An inspiration engine for ideas
Open AI
@openai

Meta presents MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
- Dividesy expert modules into modality-specific groups
- Achieves better performance than the baseline MoE
abs: https://t.co/aXWVr0plp9
alphaxiv:... See more
AI Education
J SADLER • 1 card


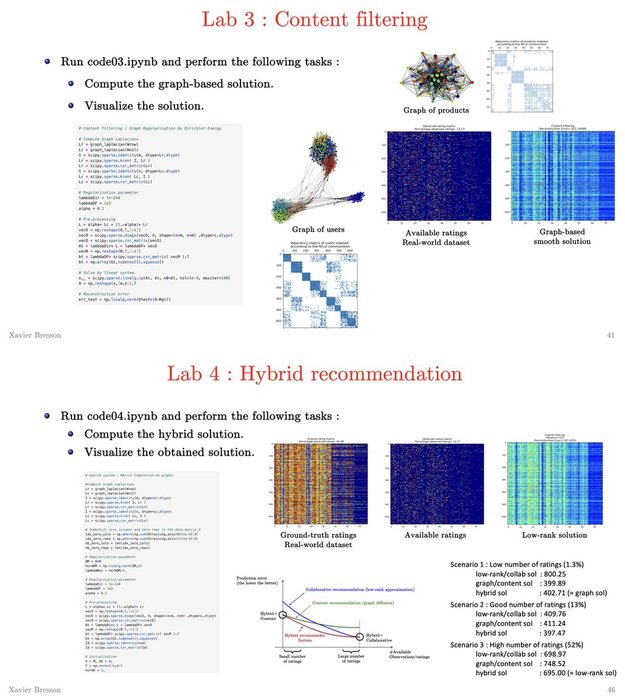
Notebooks for Lecture 5 on Recommendation on Graphs
Lab1: Google PageRank
https://t.co/WtbFZdzmou
Lab2: Collaborative/low-rank recom
https://t.co/QdRsseuSAd
Lab3: Content/graph-Dirichlet... See more
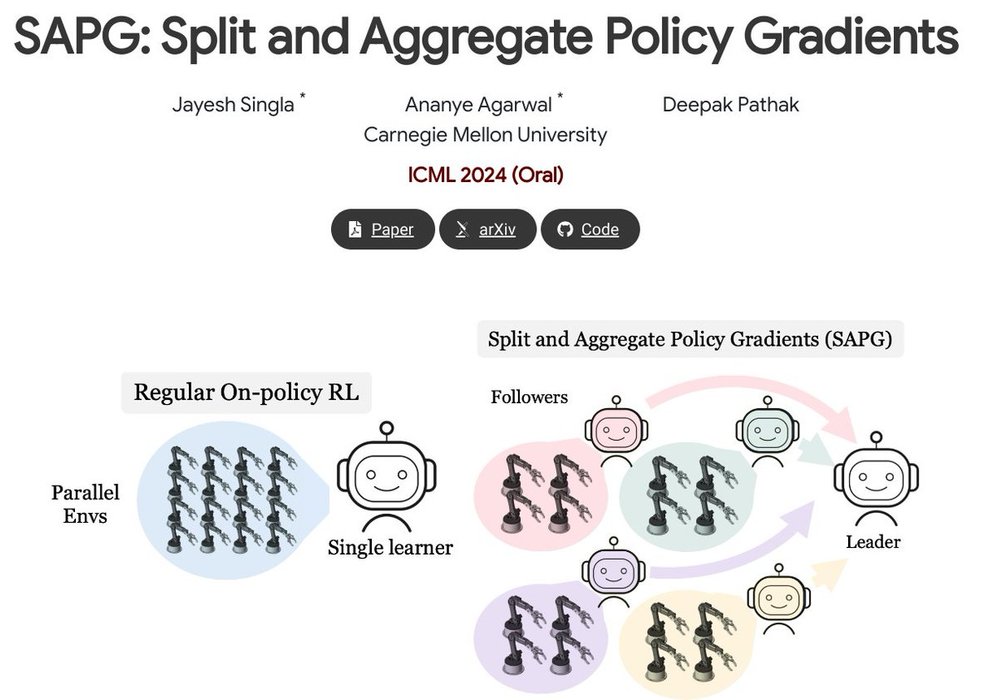
SAPG: Split and Aggregate Policy Gradients
Significantly higher performance across a variety of challenging environments where vanilla PPO and other strong baselines fail to achieve high performance
proj: https://t.co/HGFlqF8p8J
abs: https://t.co/oixKLELgji... See more





My lecture notes on regularization techniques in machine learning
https://t.co/27tRxkieYx
Check out the section on double descent suggested by @ylecun :) https://t.co/s7JPRPEHCP