Sublime
An inspiration engine for ideas

We worked with the @calai_app team to train a custom calorie estimation model for their core user flows.
Today, this custom model powers 100% of their traffic, serving millions of users worldwide.
The model is:
- Better than GPT5
- 3x faster
- 50%... See more

We've partnered with Modular to create Large Scale Inference (LSI), a new OpenAI-compatible inference service.
It's up to 85% cheaper than other offerings & can handle trillion-token scale.
We originally created it at the request of a major AI lab to do large scale multimodal synthetic data... See more

Excited to release new repo: nanochat!
(it's among the most unhinged I've written).
Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot... See more
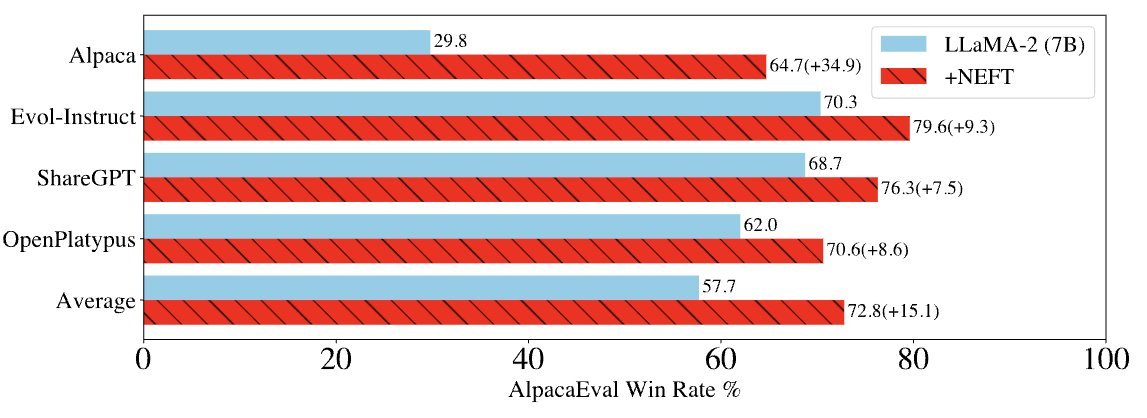
🚨 This one simple trick will level up your LLM🚀🚀
Wait...don't go. This isn't a blue check grifter tweet!
Instruction tuning with this easy trick will *actually* boost AlpacaEval scores, even for large (70B) and llama2-chat base models…by a lot 🧵 https://t.co/1OBMENFSxb
📜🚨📜🚨
NN loss landscapes are full of permutation symmetries, ie. swap any 2 units in a hidden layer. What does this mean for SGD? Is this practically useful?
For the past 5 yrs these Qs have fascinated me. Today, I am ready to announce "Git Re-Basin"!
https://t.co/mRu5k3ONUm... See more
Samuel "curry-howard fanboi" Ainsworthx.com
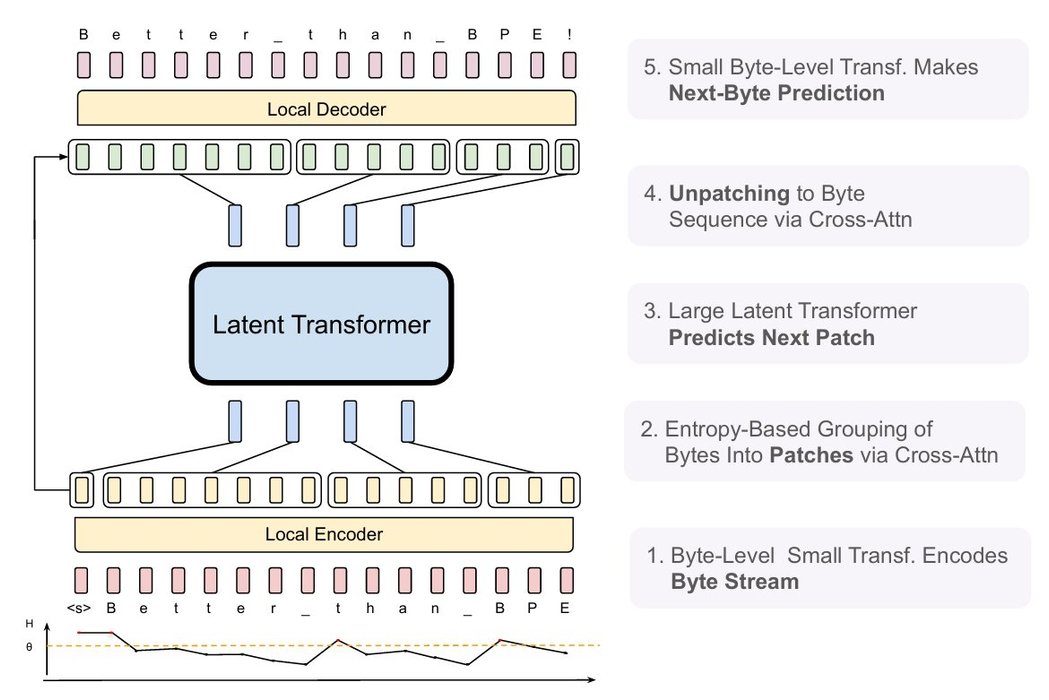
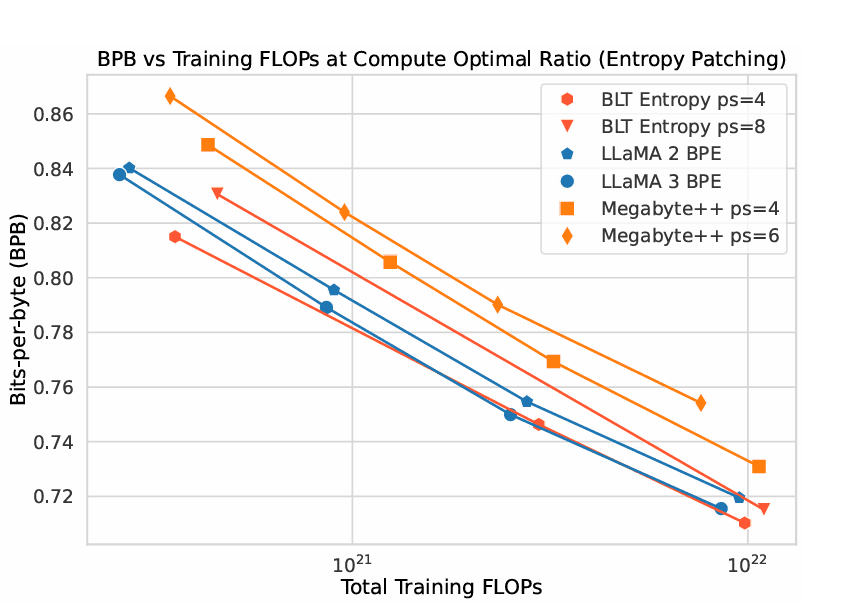
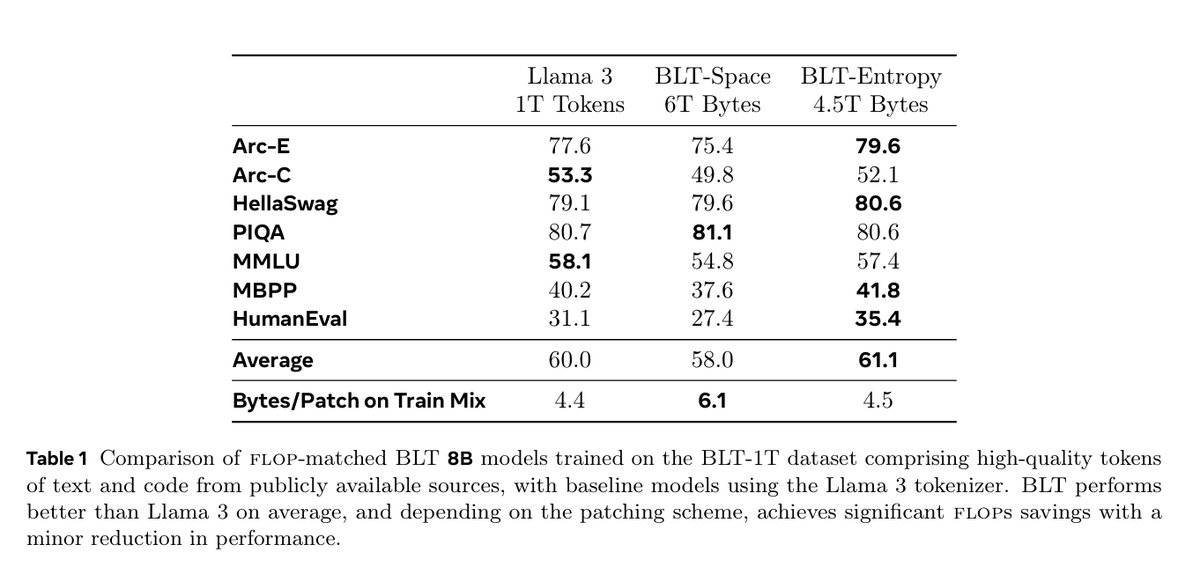
META JUST KILLED TOKENIZATION !!!
A few hours ago they released "Byte Latent Transformer". A tokenizer free architecture that dynamically encodes Bytes into Patches and achieves better inference efficiency and robustness!
(I was just talking about how we need dynamic tokenization that is... See more
