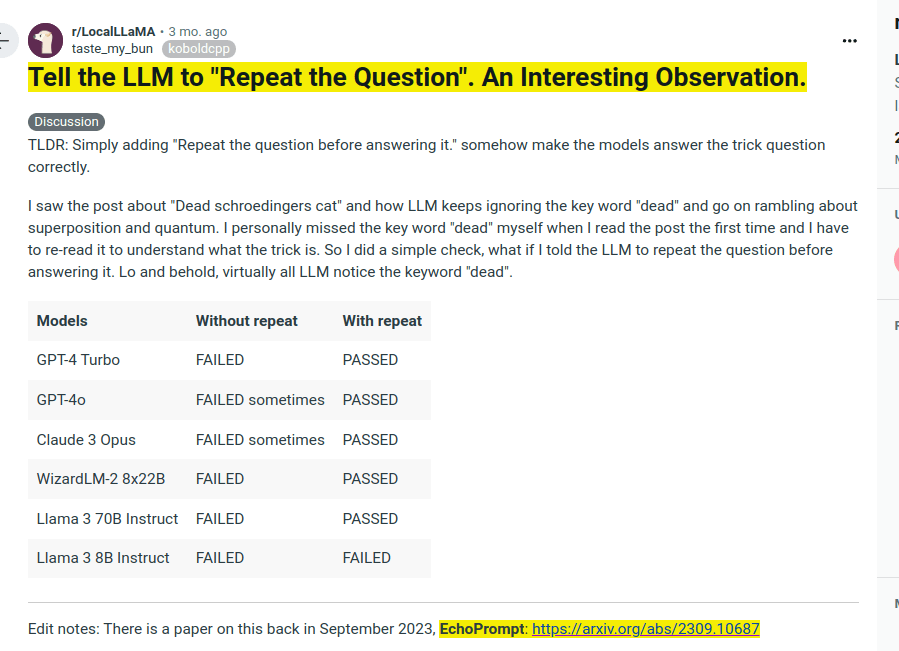
Simply adding "Repeat the question before answering it." somehow make the models answer the trick question correctly. 🤔
Probable explanations:✨
📌 Repeating the question in the model's context, significantly increasing the likelihood of the model detecting any potential "gotchas."
📌 One hypothesis is that maybe it puts the model into more of a completion mode vs answering from a chat instruct mode.
📌 Another, albeit less likely, reason could be that the model might assume the user’s question contains mistakes (e.g., the user intended to ask about a Schrödinger cat instead of a dead cat). However, if the question is in the assistant’s part of the context, the model trusts it to be accurate.
📚 The related Paper is EchoPrompt which proposes this techniques to rephrase original Prompt/queries before answering them.
improves the Zero-shot-CoT performance of code-davinci-002 by 5% in numerical tasks and 13% in reading comprehension tasks.