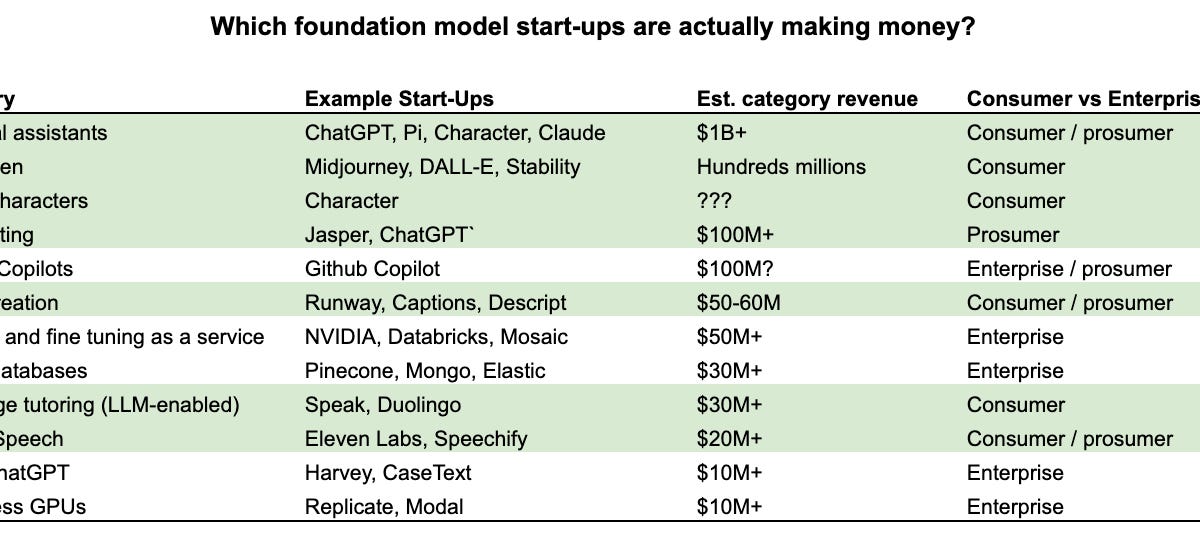
The end of incrementalism: how AI will reward maximalist start-upsPhilip Clarkphilipjclark.substack.comSaved by Bella Cusi and 1 other