TabLib
approximatelabs.com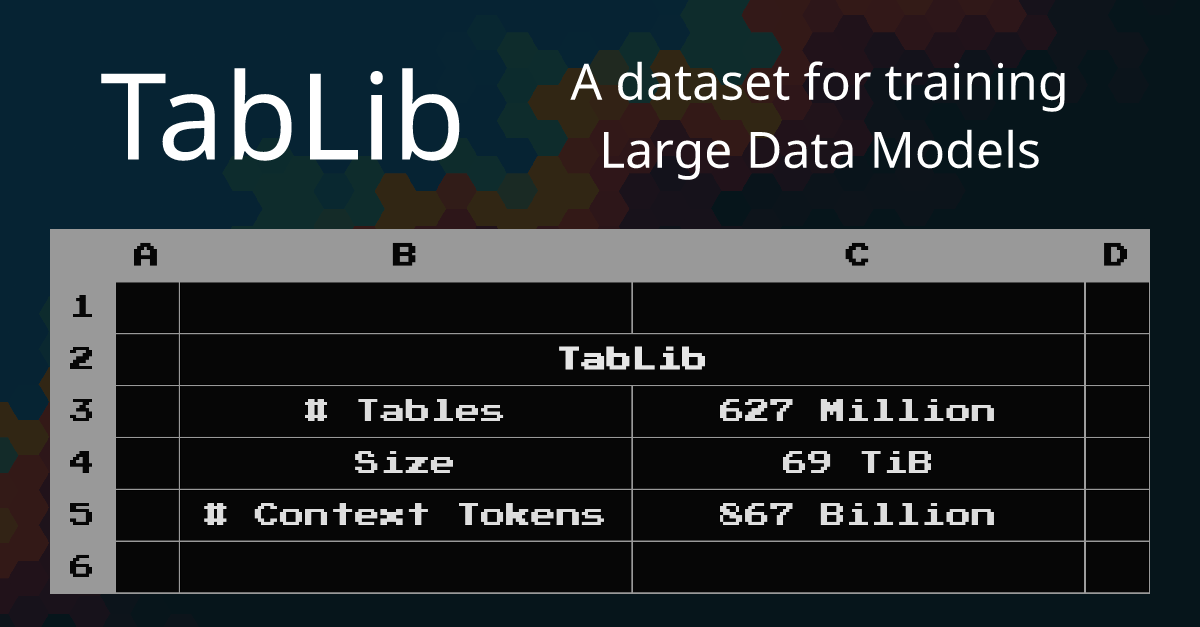
TabLib
Nicolay Gerold added
Nicolay Gerold added
Nicolay Gerold added
Nicolay Gerold added
Nicolay Gerold added
Nicolay Gerold added
Darren LI added
Following the open data movement, often embracing a not-for-profit philosophy, many data sets are available online from fields like biodiversity, business, cartography, chemistry, genomics, and medicine. Look at one central index, www.kdnuggets.com/datasets, and you’ll see what amounts to lists of lists of data resources.