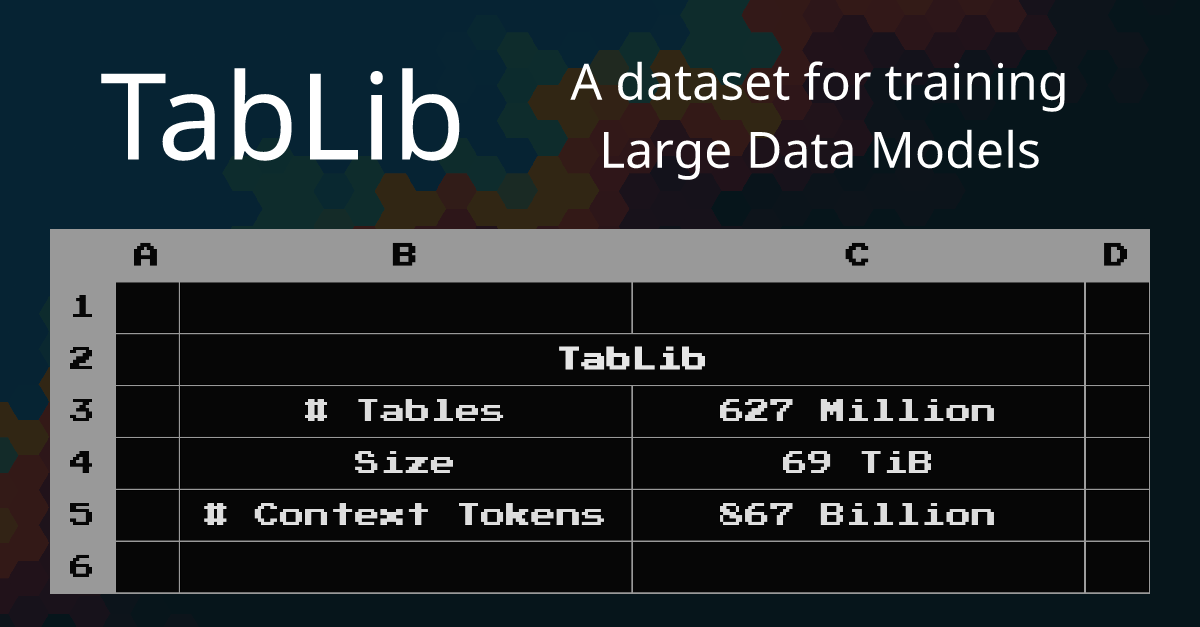
TabLib
TabLib
approximatelabs.com
Related
Insights
Highlights