r/LocalLLaMA - Reddit
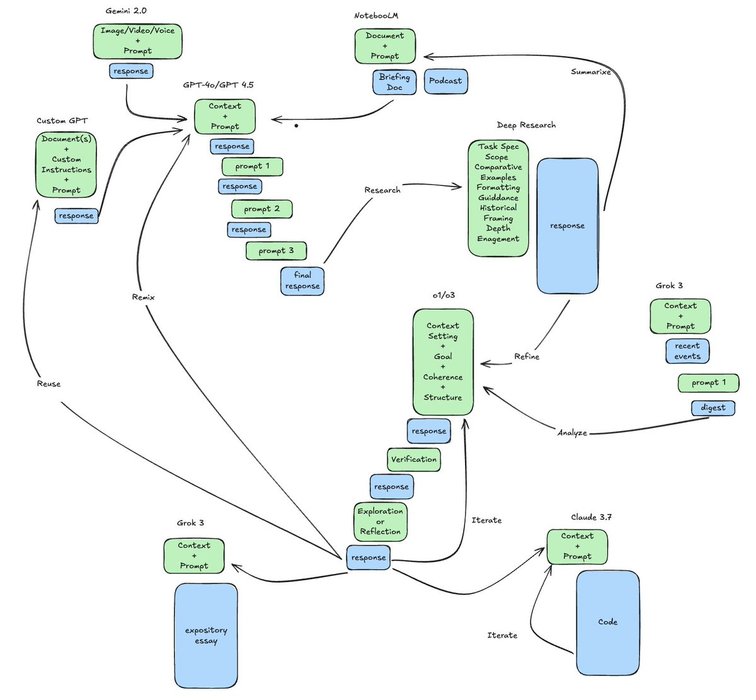
I mined Andrej Karpathy's "How I use LLMs" video for some addition things he does and I've updated the diagram.
Using multiple LLMs as an "LLM council"
Consults multiple LLMs by asking them the same question and synthesizes the responses. For example, when seeking travel recommendations, they ask Gemini,... See more
Want to run LLMs locally on your Laptop?🤖💻
Here's a quick overview of the 5 best frameworks to run LLMs locally:
1. Ollama
Ollama allows you to run LLMs locally through your command line and is probably the easiest framework to get started... See more
Patrick Loeberx.comIs @ollama still the best way to run LLAMA 3 locally? How can I get it to run in a ChatGPT style UX locally?
Peter Yangx.comeneral-purpose models
- 1.1B: TinyDolphin 2.8 1.1B. Takes about ~700MB RAM and tested on my Pi 4 with 2 gigs of RAM. Hallucinates a lot, but works for basic conversation.
- 2.7B: Dolphin 2.6 Phi-2. Takes over ~2GB RAM and tested on my 3GB 32-bit phone via llama.cpp on Termux.
- 7B: Nous Hermes Mistral 7B DPO. Takes about ~4-5GB RAM depending on
r/LocalLLaMA - Reddit
- If you are looking to develop an AI application, and you have a Mac or Linux machine, Ollama is great because it’s very easy to set up, easy to work with, and fast.
- If you are looking to chat locally with documents, GPT4All is the best out of the box solution that is also easy to set up
- If you are looking for advanced control and insight into neural