GitHub - okuvshynov/slowllama: Finetune llama2-70b and codellama on MacBook Air without quantization
⚡ LitGPT
Pretrain, finetune, evaluate, and deploy 20+ LLMs on your own data
Uses the latest state-of-the-art techniques:
✅ flash attention ✅ fp4/8/16/32 ✅ LoRA, QLoRA, Adapter (v1, v2) ✅ FSDP ✅ 1-1000+ GPUs/TPUs
Lightning AI • Models • Quick start • Inference • Finetune • Pretrain • Deploy • Features • Training recipes (YAML)
Finetune, pretrain and d... See more
Pretrain, finetune, evaluate, and deploy 20+ LLMs on your own data
Uses the latest state-of-the-art techniques:
✅ flash attention ✅ fp4/8/16/32 ✅ LoRA, QLoRA, Adapter (v1, v2) ✅ FSDP ✅ 1-1000+ GPUs/TPUs
Lightning AI • Models • Quick start • Inference • Finetune • Pretrain • Deploy • Features • Training recipes (YAML)
Finetune, pretrain and d... See more
Lightning-AI • GitHub - Lightning-AI/litgpt: Pretrain, finetune, deploy 20+ LLMs on your own data. Uses state-of-the-art techniques: flash attention, FSDP, 4-bit, LoRA, and more.
StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more.
mit-han-lab • GitHub - mit-han-lab/streaming-llm: Efficient Streaming Language Models with Attention Sinks
Ollama
ollama.com
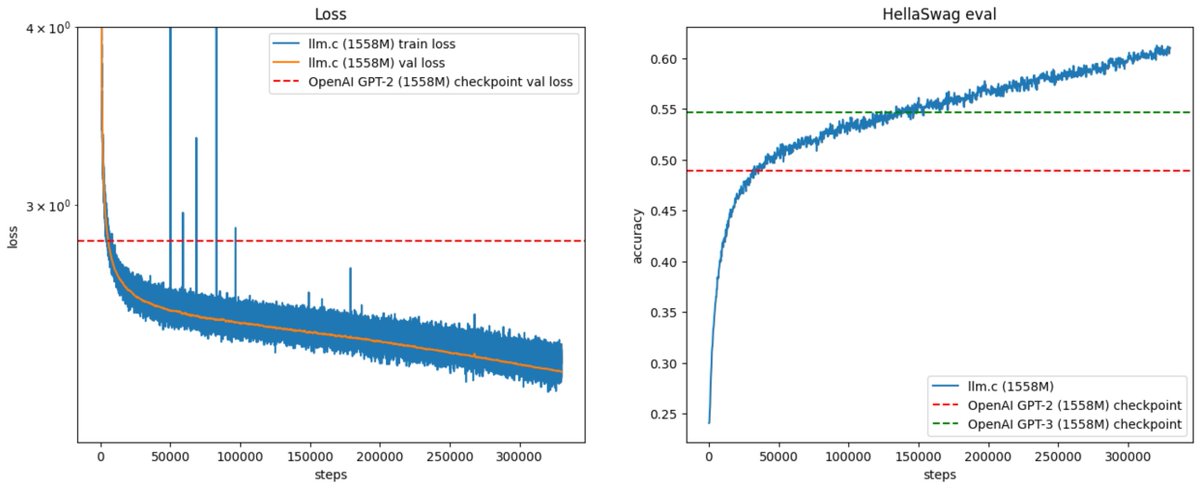
In 2019, OpenAI announced GPT-2 with this post:
https://t.co/jjP8IXmu8D
Today (~5 years later) you can train your own for ~$672, running on one 8XH100 GPU node for 24 hours. Our latest llm.c post gives the walkthrough in some detail:
https://t.co/XjLWE2P0Hp... See more
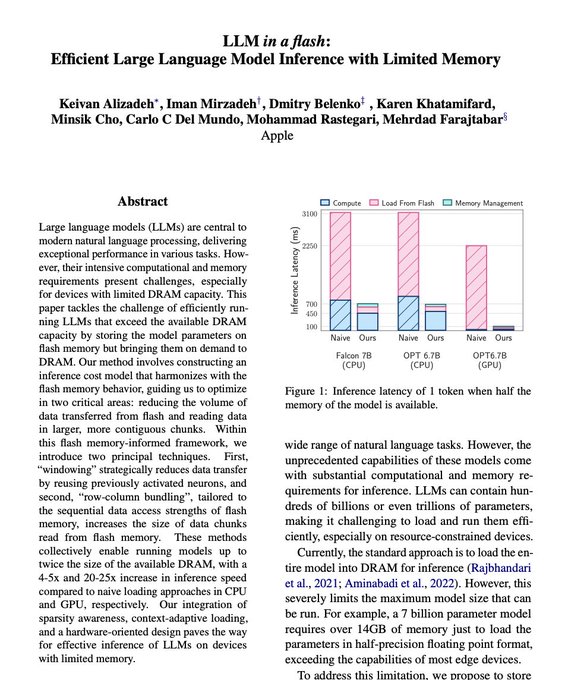
Apple announces LLM in a flash: Efficient Large Language Model Inference with Limited Memory
paper page: https://huggingface.co/papers/2312.11514... See more
GitHub - mit-han-lab/streaming-llm: Efficient Streaming Language Models with Attention Sinks
mit-han-labgithub.comLlama 2 - Resource Overview - Meta AI
ai.meta.com
How I run LLMs locally
abishekmuthian.com