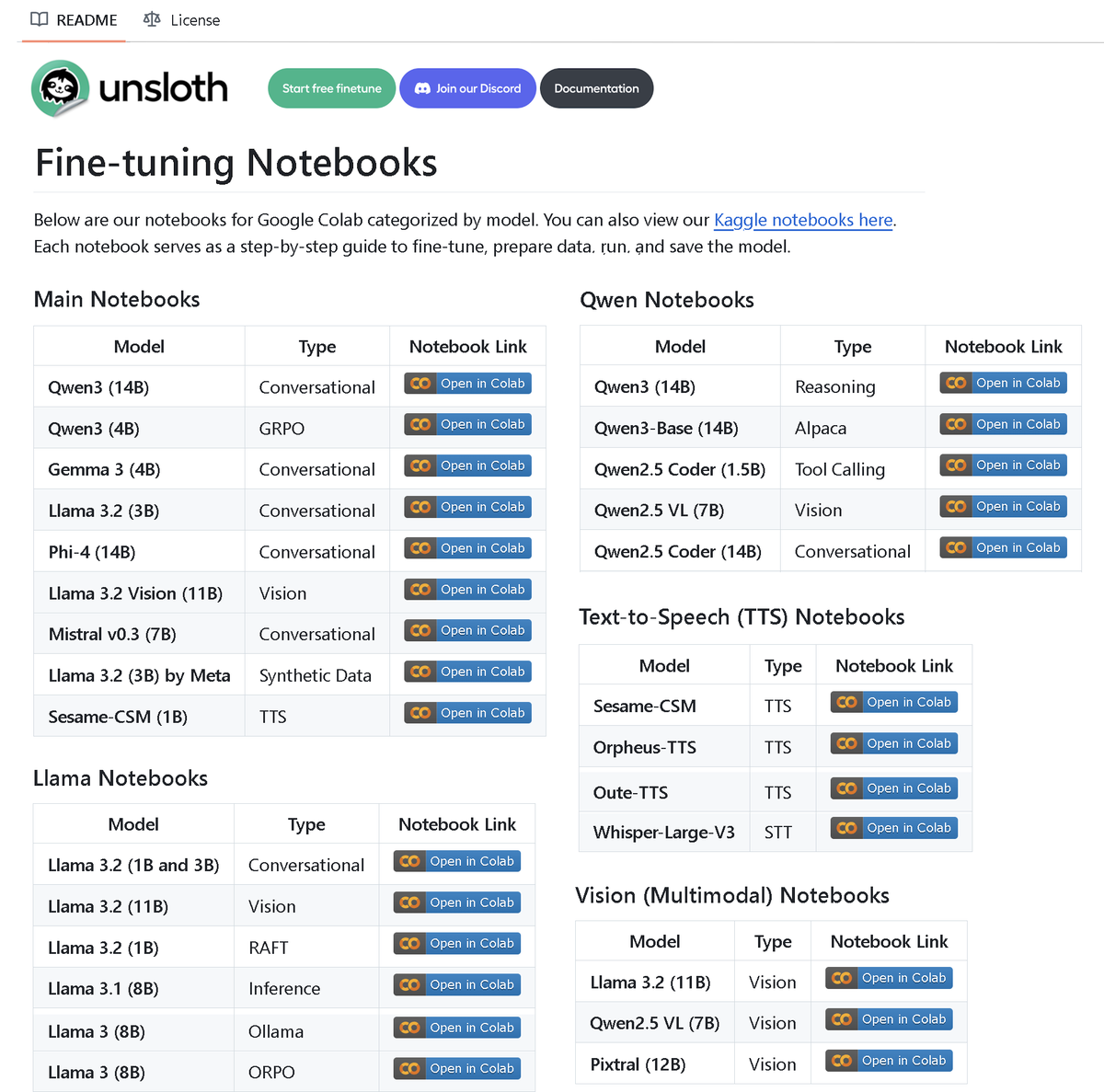
We made a repo with 100+ Fine-tuning notebooks all in once place!
Has guides & examples for:
• Tool-calling, Classification, Synthetic data
• BERT, TTS, Vision LLMs
• GRPO, DPO, SFT, CPT
• Dataprep, eval, saving
• Llama, Qwen, Gemma, Phi,... See more